10 KiB
![]()


简体中文 | English
A Deep Learning Based Knowledge Extraction Toolkit for Knowledge Base Population
DeepKE is a knowledge extraction toolkit supporting low-resource and document-level scenarios. It provides three functions based PyTorch, including Named Entity Recognition, Relation Extraciton and Attribute Extraction.
Online Demo
Prediction
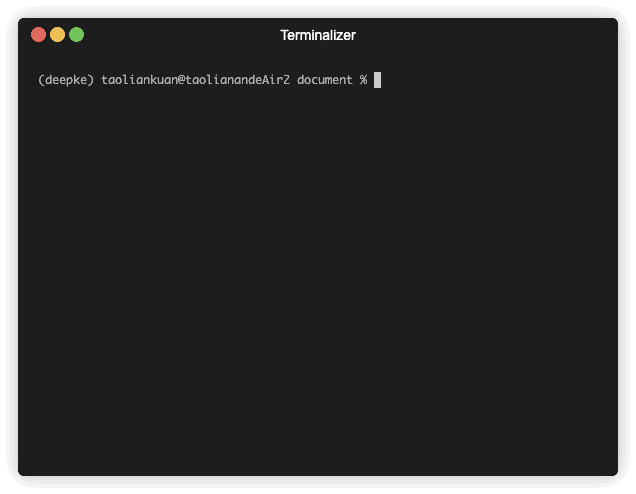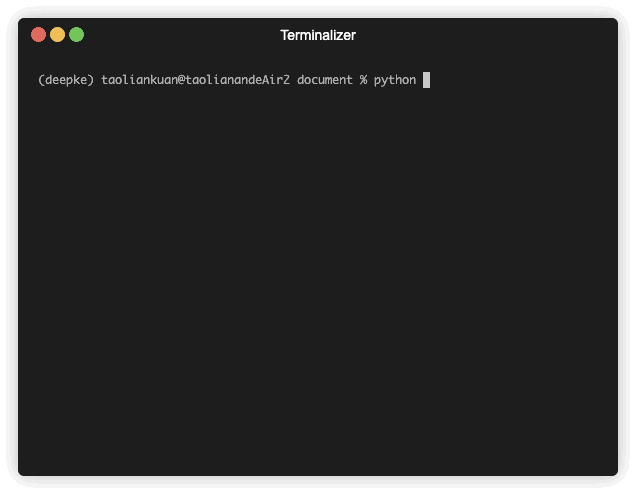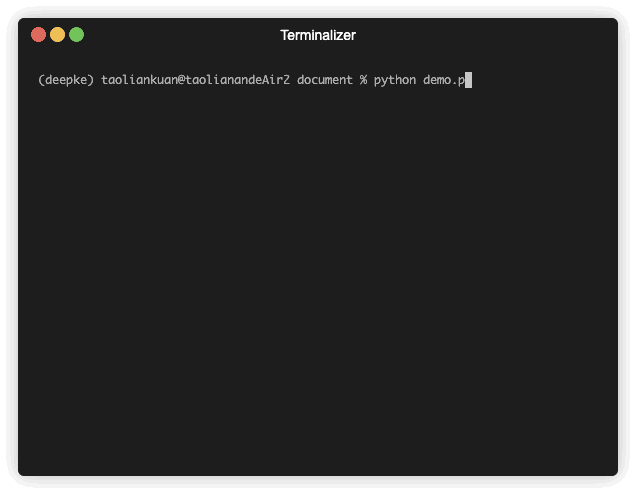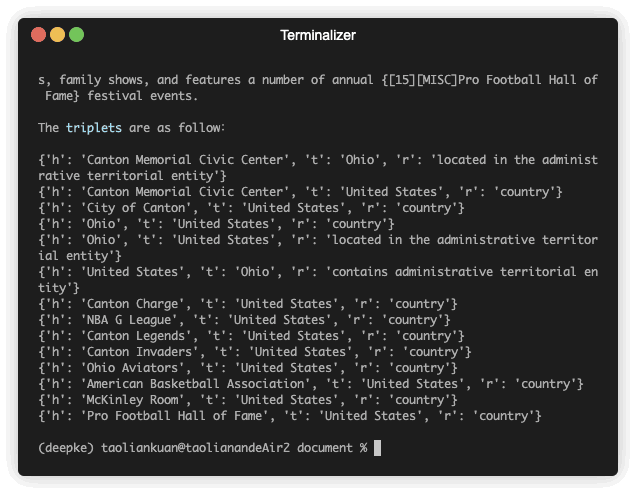
There is a demonstration of prediction.
Model Framework

Figure 1: The framework of DeepKE
- DeepKE contains three modules for named entity recognition, relation extraction and attribute extraction, the three tasks respectively.
- Each module has its own submodules. For example, there are standard, document-level and few-shot submodules in the attribute extraction modular.
- Each submodule compose of three parts: a collection of tools, which can function as tokenizer, dataloader, preprocessor and the like, a encoder and a part for training and prediction
Quickstart
Take the fully supervised attribute extraction for example.
-
Download basic codes
git clone https://github.com/zjunlp/DeepKE.git -
Create a virtual environment (recommend
anaconda)conda create -n deepke python=3.8 -
Enter the environment
conda activate deepke -
Install dependent packages
- If use deepke directly:
pip install deepke - If modify source codes before usage:
run
python setup.py installfirstly, after modification, runpython setup.py develop
- If use deepke directly:
-
Enter the corresponding directory
cd DeepKE/example/re/standard -
Train
python run.py(Parameters for training can be changed in theconffolder) -
Predict
python predict.py(Parameters for prediction can be changed in theconffolder)
Requirements
python == 3.8
- torch == 1.5
- hydra-core == 1.0.6
- tensorboard == 2.4.1
- matplotlib == 3.4.1
- transformers == 3.4.0
- jieba == 0.42.1
- scikit-learn == 0.24.1
- pytorch-transformers == 1.2.0
- seqeval == 1.2.2
- tqdm == 4.60.0
- opt-einsum==3.3.0
- ujson
Introduction of Three Functions
1. Named Entity Recognition
-
Named entity recognition seeks to locate and classify named entities mentioned in unstructured text into pre-defined categories such as person names, organizations, locations, organizations, etc.
-
The data is stored in
.txtfiles. Some instances as following:Sentence Person Location Organization 本报北京9月4日讯记者杨涌报道:部分省区人民日报宣传发行工作座谈会9月3日在4日在京举行。 杨涌 北京 人民日报 《红楼梦》是中央电视台和中国电视剧制作中心根据中国古典文学名著《红楼梦》摄制于1987年的一部古装连续剧,由王扶林导演,周汝昌、王蒙、周岭等多位红学家参与制作。 王扶林,周汝昌,王蒙,周岭 中国 中央电视台,中国电视剧制作中心 秦始皇兵马俑位于陕西省西安市,1961年被国务院公布为第一批全国重点文物保护单位,是世界八大奇迹之一。 秦始皇 陕西省,西安市 国务院 -
Read the detailed process in specific README
- STANDARD (Fully Supervised)
- The standard module is implemented by the pretrained model BERT.
- Enter
DeepKE/example/ner/standard. - The dataset and parameters can be customized in the
datafolder andconffolder respectively. - Train:
python run.py - Predict:
python predict.py
- FEW-SHOT
- This module is in the low-resouce scenario.
- Enter
DeepKE/example/ner/few-shot. - The directory where the model is loaded and saved and the configuration parameters can be cusomized in the
conffolder. - Train with CoNLL-2003:
python run.py - Train in the few-shot scenario:
python run.py +train=few_shot. Users can modifyload_pathinconf/train/few_shot.yamlwith the use of existing loaded model. - Predict: add
- predicttoconf/config.yaml, modifyloda_pathas the model path andwrite_pathas the path where the predicted results are saved inconf/predict.yaml, and then runpython predict.py
- STANDARD (Fully Supervised)
2. Relation Extraction
-
Relationship extraction is the task of extracting semantic relations between entities from a unstructured text.
-
The data is stored in
.csvfiles. Some instances as following:Sentence Relation Head Head_offset Tail Tail_offset 《岳父也是爹》是王军执导的电视剧,由马恩然、范明主演。 导演 岳父也是爹 1 王军 8 《九玄珠》是在纵横中文网连载的一部小说,作者是龙马。 连载网站 九玄珠 1 纵横中文网 7 提起杭州的美景,西湖总是第一个映入脑海的词语。 所在城市 西湖 8 杭州 2 -
Read the detailed process in specific README
-
- The standard module is implemented by common deep learning models, including CNN, RNN, Capsule, GCN, Transformer and the pretrained model.
- Enter the
DeepKE/example/re/standardfolder. - The dataset and parameters can be customized in the
datafolder andconffolder respectively. - Train:
python run.py - Predict:
python predict.py
-
- This module is in the low-resouce scenario.
- Enter
DeepKE/example/re/few-shot. - Train:
python run.pyStart with the model trained last time: modifytrain_from_saved_modelinconf/train.yamlas the path where the model trained last time was saved. And the path saving logs generated in training can be customized bylog_dir. - Predict:
python predict.py
-
- Download the model
train_distant.jsonfrom Google Drive todata/. - Enter
DeepKE/example/re/document. - Train:
python run.pyStart with the model trained last time: modifytrain_from_saved_modelinconf/train.yamlas the path where the model trained last time was saved. And the path saving logs generated in training can be customized bylog_dir. - Predict:
python predict.py
- Download the model
-
3. Attribute Extraction
-
Attribute extraction is to extract attributes for entities in a unstructed text.
-
The data is stored in
.csvfiles. Some instances as following:Sentence Att Ent Ent_offset Val Val_offset 张冬梅,女,汉族,1968年2月生,河南淇县人 民族 张冬梅 0 汉族 6 杨缨,字绵公,号钓溪,松溪县人,祖籍将乐,是北宋理学家杨时的七世孙 朝代 杨缨 0 北宋 22 2014年10月1日许鞍华执导的电影《黄金时代》上映 上映时间 黄金时代 19 2014年10月1日 0 -
Read the detailed process in specific README
- STANDARD (Fully Supervised)
- The standard module is implemented by common deep learning models, including CNN, RNN, Capsule, GCN, Transformer and the pretrained model.
- Enter the
DeepKE/example/ae/standardfolder. - The dataset and parameters can be customized in the
datafolder andconffolder respectively. - Train:
python run.py - Predict:
python predict.py
- STANDARD (Fully Supervised)
Tips
- Using nearest mirror, like THU in China, will speed up the installation of Anaconda.
- Using nearest mirror, like aliyun in China, will speed up
pip install XXX. - When encountering
ModuleNotFoundError: No module named 'past',runpip install future. - It's slow to install the pretrained language models online. Recommend download pretrained models before use and save them in the
pretrainedfolder. ReadREADME.mdin every task directory to check the specific requirement for saving pretrained models.
Developers
Zhejiang University: Ningyu Zhang, Liankuan Tao, Haiyang Yu, Xiang Chen, Xin Xu, Xi Tian, Lei Li, Zhoubo Li, Shumin Deng, Yunzhi Yao, Hongbin Ye, Xin Xie, Guozhou Zheng, Huajun Chen
Alibaba DAMO: Chuanqi Tan, Fei Huang