Merge branch 'develop' into develop
This commit is contained in:
commit
fee2c17bf7
|
|
@ -3,10 +3,8 @@ English | [简体中文](README_cn.md)
|
|||
## Introduction
|
||||
PaddleOCR aims to create rich, leading, and practical OCR tools that help users train better models and apply them into practice.
|
||||
|
||||
**Live stream on coming day**: July 21, 2020 at 8 pm BiliBili station live stream
|
||||
|
||||
**Recent updates**
|
||||
|
||||
- 2020.7.23, Release the playback and PPT of live class on BiliBili station, PaddleOCR Introduction, [address](https://aistudio.baidu.com/aistudio/course/introduce/1519)
|
||||
- 2020.7.15, Add mobile App demo , support both iOS and Android ( based on easyedge and Paddle Lite)
|
||||
- 2020.7.15, Improve the deployment ability, add the C + + inference , serving deployment. In addtion, the benchmarks of the ultra-lightweight OCR model are provided.
|
||||
- 2020.7.15, Add several related datasets, data annotation and synthesis tools.
|
||||
|
|
@ -214,3 +212,4 @@ We welcome all the contributions to PaddleOCR and appreciate for your feedback v
|
|||
- Many thanks to [lyl120117](https://github.com/lyl120117) for contributing the code for printing the network structure.
|
||||
- Thanks [xiangyubo](https://github.com/xiangyubo) for contributing the handwritten Chinese OCR datasets.
|
||||
- Thanks [authorfu](https://github.com/authorfu) for contributing Android demo and [xiadeye](https://github.com/xiadeye) contributing iOS demo, respectively.
|
||||
- Thanks [BeyondYourself](https://github.com/BeyondYourself) for contributing many great suggestions and simplifying part of the code style.
|
||||
|
|
|
|||
|
|
@ -3,9 +3,8 @@
|
|||
## 简介
|
||||
PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力使用者训练出更好的模型,并应用落地。
|
||||
|
||||
**直播预告:2020年7月21日晚8点B站直播,PaddleOCR开源大礼包全面解读,直播地址当天更新**
|
||||
|
||||
**近期更新**
|
||||
- 2020.7.23 发布7月21日B站直播课回放和PPT,PaddleOCR开源大礼包全面解读,[获取地址](https://aistudio.baidu.com/aistudio/course/introduce/1519)
|
||||
- 2020.7.15 添加基于EasyEdge和Paddle-Lite的移动端DEMO,支持iOS和Android系统
|
||||
- 2020.7.15 完善预测部署,添加基于C++预测引擎推理、服务化部署和端侧部署方案,以及超轻量级中文OCR模型预测耗时Benchmark
|
||||
- 2020.7.15 整理OCR相关数据集、常用数据标注以及合成工具
|
||||
|
|
@ -206,8 +205,9 @@ PaddleOCR文本识别算法的训练和使用请参考文档教程中[模型训
|
|||
## 贡献代码
|
||||
我们非常欢迎你为PaddleOCR贡献代码,也十分感谢你的反馈。
|
||||
|
||||
- 非常感谢 [Khanh Tran](https://github.com/xxxpsyduck) 贡献了英文文档。
|
||||
- 非常感谢 [Khanh Tran](https://github.com/xxxpsyduck) 贡献了英文文档
|
||||
- 非常感谢 [zhangxin](https://github.com/ZhangXinNan)([Blog](https://blog.csdn.net/sdlypyzq)) 贡献新的可视化方式、添加.gitgnore、处理手动设置PYTHONPATH环境变量的问题
|
||||
- 非常感谢 [lyl120117](https://github.com/lyl120117) 贡献打印网络结构的代码
|
||||
- 非常感谢 [xiangyubo](https://github.com/xiangyubo) 贡献手写中文OCR数据集
|
||||
- 非常感谢 [authorfu](https://github.com/authorfu) 贡献Android和[xiadeye](https://github.com/xiadeye) 贡献IOS的demo代码
|
||||
- 非常感谢 [BeyondYourself](https://github.com/BeyondYourself) 给PaddleOCR提了很多非常棒的建议,并简化了PaddleOCR的部分代码风格。
|
||||
|
|
|
|||
|
|
@ -3,11 +3,11 @@ import java.security.MessageDigest
|
|||
apply plugin: 'com.android.application'
|
||||
|
||||
android {
|
||||
compileSdkVersion 28
|
||||
compileSdkVersion 29
|
||||
defaultConfig {
|
||||
applicationId "com.baidu.paddle.lite.demo.ocr"
|
||||
minSdkVersion 15
|
||||
targetSdkVersion 28
|
||||
minSdkVersion 23
|
||||
targetSdkVersion 29
|
||||
versionCode 1
|
||||
versionName "1.0"
|
||||
testInstrumentationRunner "android.support.test.runner.AndroidJUnitRunner"
|
||||
|
|
@ -39,9 +39,8 @@ android {
|
|||
|
||||
dependencies {
|
||||
implementation fileTree(include: ['*.jar'], dir: 'libs')
|
||||
implementation 'com.android.support:appcompat-v7:28.0.0'
|
||||
implementation 'com.android.support.constraint:constraint-layout:1.1.3'
|
||||
implementation 'com.android.support:design:28.0.0'
|
||||
implementation 'androidx.appcompat:appcompat:1.1.0'
|
||||
implementation 'androidx.constraintlayout:constraintlayout:1.1.3'
|
||||
testImplementation 'junit:junit:4.12'
|
||||
androidTestImplementation 'com.android.support.test:runner:1.0.2'
|
||||
androidTestImplementation 'com.android.support.test.espresso:espresso-core:3.0.2'
|
||||
|
|
|
|||
|
|
@ -14,10 +14,10 @@
|
|||
android:roundIcon="@mipmap/ic_launcher_round"
|
||||
android:supportsRtl="true"
|
||||
android:theme="@style/AppTheme">
|
||||
<!-- to test MiniActivity, change this to com.baidu.paddle.lite.demo.ocr.MiniActivity -->
|
||||
<activity android:name="com.baidu.paddle.lite.demo.ocr.MainActivity">
|
||||
<intent-filter>
|
||||
<action android:name="android.intent.action.MAIN"/>
|
||||
|
||||
<category android:name="android.intent.category.LAUNCHER"/>
|
||||
</intent-filter>
|
||||
</activity>
|
||||
|
|
@ -25,6 +25,15 @@
|
|||
android:name="com.baidu.paddle.lite.demo.ocr.SettingsActivity"
|
||||
android:label="Settings">
|
||||
</activity>
|
||||
<provider
|
||||
android:name="androidx.core.content.FileProvider"
|
||||
android:authorities="com.baidu.paddle.lite.demo.ocr.fileprovider"
|
||||
android:exported="false"
|
||||
android:grantUriPermissions="true">
|
||||
<meta-data
|
||||
android:name="android.support.FILE_PROVIDER_PATHS"
|
||||
android:resource="@xml/file_paths"></meta-data>
|
||||
</provider>
|
||||
</application>
|
||||
|
||||
</manifest>
|
||||
|
|
@ -30,7 +30,7 @@ Java_com_baidu_paddle_lite_demo_ocr_OCRPredictorNative_init(JNIEnv *env, jobject
|
|||
}
|
||||
|
||||
/**
|
||||
* "LITE_POWER_HIGH" 转为 paddle::lite_api::LITE_POWER_HIGH
|
||||
* "LITE_POWER_HIGH" convert to paddle::lite_api::LITE_POWER_HIGH
|
||||
* @param cpu_mode
|
||||
* @return
|
||||
*/
|
||||
|
|
|
|||
|
|
@ -37,7 +37,7 @@ int OCR_PPredictor::init_from_file(const std::string &det_model_path, const std:
|
|||
return RETURN_OK;
|
||||
}
|
||||
/**
|
||||
* 调试用,保存第一步的框选结果
|
||||
* for debug use, show result of First Step
|
||||
* @param filter_boxes
|
||||
* @param boxes
|
||||
* @param srcimg
|
||||
|
|
|
|||
|
|
@ -12,26 +12,26 @@
|
|||
namespace ppredictor {
|
||||
|
||||
/**
|
||||
* 配置
|
||||
* Config
|
||||
*/
|
||||
struct OCR_Config {
|
||||
int thread_num = 4; // 线程数
|
||||
int thread_num = 4; // Thread num
|
||||
paddle::lite_api::PowerMode mode = paddle::lite_api::LITE_POWER_HIGH; // PaddleLite Mode
|
||||
};
|
||||
|
||||
/**
|
||||
* 一个四边形内图片的推理结果,
|
||||
* PolyGone Result
|
||||
*/
|
||||
struct OCRPredictResult {
|
||||
std::vector<int> word_index; //
|
||||
std::vector<int> word_index;
|
||||
std::vector<std::vector<int>> points;
|
||||
float score;
|
||||
};
|
||||
|
||||
/**
|
||||
* OCR 一共有2个模型进行推理,
|
||||
* 1. 使用第一个模型(det),框选出多个四边形
|
||||
* 2. 从原图从抠出这些多边形,使用第二个模型(rec),获取文本
|
||||
* OCR there are 2 models
|
||||
* 1. First model(det),select polygones to show where are the texts
|
||||
* 2. crop from the origin images, use these polygones to infer
|
||||
*/
|
||||
class OCR_PPredictor : public PPredictor_Interface {
|
||||
public:
|
||||
|
|
@ -50,7 +50,7 @@ public:
|
|||
int init(const std::string &det_model_content, const std::string &rec_model_content);
|
||||
int init_from_file(const std::string &det_model_path, const std::string &rec_model_path);
|
||||
/**
|
||||
* 返回OCR结果
|
||||
* Return OCR result
|
||||
* @param dims
|
||||
* @param input_data
|
||||
* @param input_len
|
||||
|
|
@ -69,7 +69,7 @@ public:
|
|||
private:
|
||||
|
||||
/**
|
||||
* 从第一个模型的结果中计算有文字的四边形
|
||||
* calcul Polygone from the result image of first model
|
||||
* @param pred
|
||||
* @param output_height
|
||||
* @param output_width
|
||||
|
|
@ -81,7 +81,7 @@ private:
|
|||
const cv::Mat &origin);
|
||||
|
||||
/**
|
||||
* 第二个模型的推理
|
||||
* infer for second model
|
||||
*
|
||||
* @param boxes
|
||||
* @param origin
|
||||
|
|
@ -91,14 +91,14 @@ private:
|
|||
infer_rec(const std::vector<std::vector<std::vector<int>>> &boxes, const cv::Mat &origin);
|
||||
|
||||
/**
|
||||
* 第二个模型提取文字的后处理
|
||||
* Postprocess or sencod model to extract text
|
||||
* @param res
|
||||
* @return
|
||||
*/
|
||||
std::vector<int> postprocess_rec_word_index(const PredictorOutput &res);
|
||||
|
||||
/**
|
||||
* 计算第二个模型的文字的置信度
|
||||
* calculate confidence of second model text result
|
||||
* @param res
|
||||
* @return
|
||||
*/
|
||||
|
|
|
|||
|
|
@ -7,7 +7,7 @@
|
|||
namespace ppredictor {
|
||||
|
||||
/**
|
||||
* PaddleLite Preditor 通用接口
|
||||
* PaddleLite Preditor Common Interface
|
||||
*/
|
||||
class PPredictor_Interface {
|
||||
public:
|
||||
|
|
@ -21,7 +21,7 @@ public:
|
|||
};
|
||||
|
||||
/**
|
||||
* 通用推理
|
||||
* Common Predictor
|
||||
*/
|
||||
class PPredictor : public PPredictor_Interface {
|
||||
public:
|
||||
|
|
@ -33,9 +33,9 @@ public:
|
|||
}
|
||||
|
||||
/**
|
||||
* 初始化paddlitelite的opt模型,nb格式,与init_paddle二选一
|
||||
* init paddlitelite opt model,nb format ,or use ini_paddle
|
||||
* @param model_content
|
||||
* @return 0 目前是固定值0, 之后其他值表示失败
|
||||
* @return 0
|
||||
*/
|
||||
virtual int init_nb(const std::string &model_content);
|
||||
|
||||
|
|
|
|||
|
|
@ -21,10 +21,10 @@ public:
|
|||
const std::vector<std::vector<uint64_t>> get_lod() const;
|
||||
const std::vector<int64_t> get_shape() const;
|
||||
|
||||
std::vector<float> data; // 通常是float返回,与下面的data_int二选一
|
||||
std::vector<int> data_int; // 少数层是int返回,与 data二选一
|
||||
std::vector<int64_t> shape; // PaddleLite输出层的shape
|
||||
std::vector<std::vector<uint64_t>> lod; // PaddleLite输出层的lod
|
||||
std::vector<float> data; // return float, or use data_int
|
||||
std::vector<int> data_int; // several layers return int ,or use data
|
||||
std::vector<int64_t> shape; // PaddleLite output shape
|
||||
std::vector<std::vector<uint64_t>> lod; // PaddleLite output lod
|
||||
|
||||
private:
|
||||
std::unique_ptr<const paddle::lite_api::Tensor> _tensor;
|
||||
|
|
|
|||
|
|
@ -19,15 +19,16 @@ package com.baidu.paddle.lite.demo.ocr;
|
|||
import android.content.res.Configuration;
|
||||
import android.os.Bundle;
|
||||
import android.preference.PreferenceActivity;
|
||||
import android.support.annotation.LayoutRes;
|
||||
import android.support.annotation.Nullable;
|
||||
import android.support.v7.app.ActionBar;
|
||||
import android.support.v7.app.AppCompatDelegate;
|
||||
import android.support.v7.widget.Toolbar;
|
||||
import android.view.MenuInflater;
|
||||
import android.view.View;
|
||||
import android.view.ViewGroup;
|
||||
|
||||
import androidx.annotation.LayoutRes;
|
||||
import androidx.annotation.Nullable;
|
||||
import androidx.appcompat.app.ActionBar;
|
||||
import androidx.appcompat.app.AppCompatDelegate;
|
||||
import androidx.appcompat.widget.Toolbar;
|
||||
|
||||
/**
|
||||
* A {@link PreferenceActivity} which implements and proxies the necessary calls
|
||||
* to be used with AppCompat.
|
||||
|
|
|
|||
|
|
@ -3,23 +3,22 @@ package com.baidu.paddle.lite.demo.ocr;
|
|||
import android.Manifest;
|
||||
import android.app.ProgressDialog;
|
||||
import android.content.ContentResolver;
|
||||
import android.content.Context;
|
||||
import android.content.Intent;
|
||||
import android.content.SharedPreferences;
|
||||
import android.content.pm.PackageManager;
|
||||
import android.database.Cursor;
|
||||
import android.graphics.Bitmap;
|
||||
import android.graphics.BitmapFactory;
|
||||
import android.media.ExifInterface;
|
||||
import android.net.Uri;
|
||||
import android.os.Bundle;
|
||||
import android.os.Environment;
|
||||
import android.os.Handler;
|
||||
import android.os.HandlerThread;
|
||||
import android.os.Message;
|
||||
import android.preference.PreferenceManager;
|
||||
import android.provider.MediaStore;
|
||||
import android.support.annotation.NonNull;
|
||||
import android.support.v4.app.ActivityCompat;
|
||||
import android.support.v4.content.ContextCompat;
|
||||
import android.support.v7.app.AppCompatActivity;
|
||||
import android.text.method.ScrollingMovementMethod;
|
||||
import android.util.Log;
|
||||
import android.view.Menu;
|
||||
|
|
@ -29,9 +28,17 @@ import android.widget.ImageView;
|
|||
import android.widget.TextView;
|
||||
import android.widget.Toast;
|
||||
|
||||
import androidx.annotation.NonNull;
|
||||
import androidx.appcompat.app.AppCompatActivity;
|
||||
import androidx.core.app.ActivityCompat;
|
||||
import androidx.core.content.ContextCompat;
|
||||
import androidx.core.content.FileProvider;
|
||||
|
||||
import java.io.File;
|
||||
import java.io.IOException;
|
||||
import java.io.InputStream;
|
||||
import java.text.SimpleDateFormat;
|
||||
import java.util.Date;
|
||||
|
||||
public class MainActivity extends AppCompatActivity {
|
||||
private static final String TAG = MainActivity.class.getSimpleName();
|
||||
|
|
@ -69,6 +76,7 @@ public class MainActivity extends AppCompatActivity {
|
|||
protected float[] inputMean = new float[]{};
|
||||
protected float[] inputStd = new float[]{};
|
||||
protected float scoreThreshold = 0.1f;
|
||||
private String currentPhotoPath;
|
||||
|
||||
protected Predictor predictor = new Predictor();
|
||||
|
||||
|
|
@ -368,18 +376,56 @@ public class MainActivity extends AppCompatActivity {
|
|||
}
|
||||
|
||||
private void takePhoto() {
|
||||
Intent takePhotoIntent = new Intent(MediaStore.ACTION_IMAGE_CAPTURE);
|
||||
if (takePhotoIntent.resolveActivity(getPackageManager()) != null) {
|
||||
startActivityForResult(takePhotoIntent, TAKE_PHOTO_REQUEST_CODE);
|
||||
Intent takePictureIntent = new Intent(MediaStore.ACTION_IMAGE_CAPTURE);
|
||||
// Ensure that there's a camera activity to handle the intent
|
||||
if (takePictureIntent.resolveActivity(getPackageManager()) != null) {
|
||||
// Create the File where the photo should go
|
||||
File photoFile = null;
|
||||
try {
|
||||
photoFile = createImageFile();
|
||||
} catch (IOException ex) {
|
||||
Log.e("MainActitity", ex.getMessage(), ex);
|
||||
Toast.makeText(MainActivity.this,
|
||||
"Create Camera temp file failed: " + ex.getMessage(), Toast.LENGTH_SHORT).show();
|
||||
}
|
||||
// Continue only if the File was successfully created
|
||||
if (photoFile != null) {
|
||||
Log.i(TAG, "FILEPATH " + getExternalFilesDir("Pictures").getAbsolutePath());
|
||||
Uri photoURI = FileProvider.getUriForFile(this,
|
||||
"com.baidu.paddle.lite.demo.ocr.fileprovider",
|
||||
photoFile);
|
||||
currentPhotoPath = photoFile.getAbsolutePath();
|
||||
takePictureIntent.putExtra(MediaStore.EXTRA_OUTPUT, photoURI);
|
||||
startActivityForResult(takePictureIntent, TAKE_PHOTO_REQUEST_CODE);
|
||||
Log.i(TAG, "startActivityForResult finished");
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
private File createImageFile() throws IOException {
|
||||
// Create an image file name
|
||||
String timeStamp = new SimpleDateFormat("yyyyMMdd_HHmmss").format(new Date());
|
||||
String imageFileName = "JPEG_" + timeStamp + "_";
|
||||
File storageDir = getExternalFilesDir(Environment.DIRECTORY_PICTURES);
|
||||
File image = File.createTempFile(
|
||||
imageFileName, /* prefix */
|
||||
".bmp", /* suffix */
|
||||
storageDir /* directory */
|
||||
);
|
||||
|
||||
return image;
|
||||
}
|
||||
|
||||
@Override
|
||||
protected void onActivityResult(int requestCode, int resultCode, Intent data) {
|
||||
super.onActivityResult(requestCode, resultCode, data);
|
||||
if (resultCode == RESULT_OK && data != null) {
|
||||
if (resultCode == RESULT_OK) {
|
||||
switch (requestCode) {
|
||||
case OPEN_GALLERY_REQUEST_CODE:
|
||||
if (data == null) {
|
||||
break;
|
||||
}
|
||||
try {
|
||||
ContentResolver resolver = getContentResolver();
|
||||
Uri uri = data.getData();
|
||||
|
|
@ -393,9 +439,22 @@ public class MainActivity extends AppCompatActivity {
|
|||
}
|
||||
break;
|
||||
case TAKE_PHOTO_REQUEST_CODE:
|
||||
Bundle extras = data.getExtras();
|
||||
Bitmap image = (Bitmap) extras.get("data");
|
||||
if (currentPhotoPath != null) {
|
||||
ExifInterface exif = null;
|
||||
try {
|
||||
exif = new ExifInterface(currentPhotoPath);
|
||||
} catch (IOException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
int orientation = exif.getAttributeInt(ExifInterface.TAG_ORIENTATION,
|
||||
ExifInterface.ORIENTATION_UNDEFINED);
|
||||
Log.i(TAG, "rotation " + orientation);
|
||||
Bitmap image = BitmapFactory.decodeFile(currentPhotoPath);
|
||||
image = Utils.rotateBitmap(image, orientation);
|
||||
onImageChanged(image);
|
||||
} else {
|
||||
Log.e(TAG, "currentPhotoPath is null");
|
||||
}
|
||||
break;
|
||||
default:
|
||||
break;
|
||||
|
|
|
|||
|
|
@ -0,0 +1,157 @@
|
|||
package com.baidu.paddle.lite.demo.ocr;
|
||||
|
||||
import android.graphics.Bitmap;
|
||||
import android.graphics.BitmapFactory;
|
||||
import android.os.Build;
|
||||
import android.os.Bundle;
|
||||
import android.os.Handler;
|
||||
import android.os.HandlerThread;
|
||||
import android.os.Message;
|
||||
import android.util.Log;
|
||||
import android.view.View;
|
||||
import android.widget.Button;
|
||||
import android.widget.ImageView;
|
||||
import android.widget.TextView;
|
||||
import android.widget.Toast;
|
||||
|
||||
import androidx.appcompat.app.AppCompatActivity;
|
||||
|
||||
import java.io.IOException;
|
||||
import java.io.InputStream;
|
||||
|
||||
public class MiniActivity extends AppCompatActivity {
|
||||
|
||||
|
||||
public static final int REQUEST_LOAD_MODEL = 0;
|
||||
public static final int REQUEST_RUN_MODEL = 1;
|
||||
public static final int REQUEST_UNLOAD_MODEL = 2;
|
||||
public static final int RESPONSE_LOAD_MODEL_SUCCESSED = 0;
|
||||
public static final int RESPONSE_LOAD_MODEL_FAILED = 1;
|
||||
public static final int RESPONSE_RUN_MODEL_SUCCESSED = 2;
|
||||
public static final int RESPONSE_RUN_MODEL_FAILED = 3;
|
||||
|
||||
private static final String TAG = "MiniActivity";
|
||||
|
||||
protected Handler receiver = null; // Receive messages from worker thread
|
||||
protected Handler sender = null; // Send command to worker thread
|
||||
protected HandlerThread worker = null; // Worker thread to load&run model
|
||||
protected volatile Predictor predictor = null;
|
||||
|
||||
private String assetModelDirPath = "models/ocr_v1_for_cpu";
|
||||
private String assetlabelFilePath = "labels/ppocr_keys_v1.txt";
|
||||
|
||||
private Button button;
|
||||
private ImageView imageView; // image result
|
||||
private TextView textView; // text result
|
||||
|
||||
@Override
|
||||
protected void onCreate(Bundle savedInstanceState) {
|
||||
super.onCreate(savedInstanceState);
|
||||
setContentView(R.layout.activity_mini);
|
||||
|
||||
Log.i(TAG, "SHOW in Logcat");
|
||||
|
||||
// Prepare the worker thread for mode loading and inference
|
||||
worker = new HandlerThread("Predictor Worker");
|
||||
worker.start();
|
||||
sender = new Handler(worker.getLooper()) {
|
||||
public void handleMessage(Message msg) {
|
||||
switch (msg.what) {
|
||||
case REQUEST_LOAD_MODEL:
|
||||
// Load model and reload test image
|
||||
if (!onLoadModel()) {
|
||||
runOnUiThread(new Runnable() {
|
||||
@Override
|
||||
public void run() {
|
||||
Toast.makeText(MiniActivity.this, "Load model failed!", Toast.LENGTH_SHORT).show();
|
||||
}
|
||||
});
|
||||
}
|
||||
break;
|
||||
case REQUEST_RUN_MODEL:
|
||||
// Run model if model is loaded
|
||||
final boolean isSuccessed = onRunModel();
|
||||
runOnUiThread(new Runnable() {
|
||||
@Override
|
||||
public void run() {
|
||||
if (isSuccessed){
|
||||
onRunModelSuccessed();
|
||||
}else{
|
||||
Toast.makeText(MiniActivity.this, "Run model failed!", Toast.LENGTH_SHORT).show();
|
||||
}
|
||||
}
|
||||
});
|
||||
break;
|
||||
}
|
||||
}
|
||||
};
|
||||
sender.sendEmptyMessage(REQUEST_LOAD_MODEL); // corresponding to REQUEST_LOAD_MODEL, to call onLoadModel()
|
||||
|
||||
imageView = findViewById(R.id.imageView);
|
||||
textView = findViewById(R.id.sample_text);
|
||||
button = findViewById(R.id.button);
|
||||
button.setOnClickListener(new View.OnClickListener() {
|
||||
@Override
|
||||
public void onClick(View v) {
|
||||
sender.sendEmptyMessage(REQUEST_RUN_MODEL);
|
||||
}
|
||||
});
|
||||
|
||||
|
||||
}
|
||||
|
||||
@Override
|
||||
protected void onDestroy() {
|
||||
onUnloadModel();
|
||||
if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.JELLY_BEAN_MR2) {
|
||||
worker.quitSafely();
|
||||
} else {
|
||||
worker.quit();
|
||||
}
|
||||
super.onDestroy();
|
||||
}
|
||||
|
||||
/**
|
||||
* call in onCreate, model init
|
||||
*
|
||||
* @return
|
||||
*/
|
||||
private boolean onLoadModel() {
|
||||
if (predictor == null) {
|
||||
predictor = new Predictor();
|
||||
}
|
||||
return predictor.init(this, assetModelDirPath, assetlabelFilePath);
|
||||
}
|
||||
|
||||
/**
|
||||
* init engine
|
||||
* call in onCreate
|
||||
*
|
||||
* @return
|
||||
*/
|
||||
private boolean onRunModel() {
|
||||
try {
|
||||
String assetImagePath = "images/5.jpg";
|
||||
InputStream imageStream = getAssets().open(assetImagePath);
|
||||
Bitmap image = BitmapFactory.decodeStream(imageStream);
|
||||
// Input is Bitmap
|
||||
predictor.setInputImage(image);
|
||||
return predictor.isLoaded() && predictor.runModel();
|
||||
} catch (IOException e) {
|
||||
e.printStackTrace();
|
||||
return false;
|
||||
}
|
||||
}
|
||||
|
||||
private void onRunModelSuccessed() {
|
||||
Log.i(TAG, "onRunModelSuccessed");
|
||||
textView.setText(predictor.outputResult);
|
||||
imageView.setImageBitmap(predictor.outputImage);
|
||||
}
|
||||
|
||||
private void onUnloadModel() {
|
||||
if (predictor != null) {
|
||||
predictor.releaseModel();
|
||||
}
|
||||
}
|
||||
}
|
||||
|
|
@ -38,7 +38,7 @@ public class Predictor {
|
|||
protected float scoreThreshold = 0.1f;
|
||||
protected Bitmap inputImage = null;
|
||||
protected Bitmap outputImage = null;
|
||||
protected String outputResult = "";
|
||||
protected volatile String outputResult = "";
|
||||
protected float preprocessTime = 0;
|
||||
protected float postprocessTime = 0;
|
||||
|
||||
|
|
@ -46,6 +46,16 @@ public class Predictor {
|
|||
public Predictor() {
|
||||
}
|
||||
|
||||
public boolean init(Context appCtx, String modelPath, String labelPath) {
|
||||
isLoaded = loadModel(appCtx, modelPath, cpuThreadNum, cpuPowerMode);
|
||||
if (!isLoaded) {
|
||||
return false;
|
||||
}
|
||||
isLoaded = loadLabel(appCtx, labelPath);
|
||||
return isLoaded;
|
||||
}
|
||||
|
||||
|
||||
public boolean init(Context appCtx, String modelPath, String labelPath, int cpuThreadNum, String cpuPowerMode,
|
||||
String inputColorFormat,
|
||||
long[] inputShape, float[] inputMean,
|
||||
|
|
@ -76,11 +86,7 @@ public class Predictor {
|
|||
Log.e(TAG, "Only BGR color format is supported.");
|
||||
return false;
|
||||
}
|
||||
isLoaded = loadModel(appCtx, modelPath, cpuThreadNum, cpuPowerMode);
|
||||
if (!isLoaded) {
|
||||
return false;
|
||||
}
|
||||
isLoaded = loadLabel(appCtx, labelPath);
|
||||
boolean isLoaded = init(appCtx, modelPath, labelPath);
|
||||
if (!isLoaded) {
|
||||
return false;
|
||||
}
|
||||
|
|
@ -132,7 +138,7 @@ public class Predictor {
|
|||
paddlePredictor = null;
|
||||
}
|
||||
isLoaded = false;
|
||||
cpuThreadNum = 4;
|
||||
cpuThreadNum = 1;
|
||||
cpuPowerMode = "LITE_POWER_HIGH";
|
||||
modelPath = "";
|
||||
modelName = "";
|
||||
|
|
@ -222,7 +228,7 @@ public class Predictor {
|
|||
for (int i = 0; i < warmupIterNum; i++) {
|
||||
paddlePredictor.runImage(inputData, width, height, channels, inputImage);
|
||||
}
|
||||
warmupIterNum = 0; // 之后不要再warm了
|
||||
warmupIterNum = 0; // do not need warm
|
||||
// Run inference
|
||||
start = new Date();
|
||||
ArrayList<OcrResultModel> results = paddlePredictor.runImage(inputData, width, height, channels, inputImage);
|
||||
|
|
@ -287,9 +293,7 @@ public class Predictor {
|
|||
if (image == null) {
|
||||
return;
|
||||
}
|
||||
// Scale image to the size of input tensor
|
||||
Bitmap rgbaImage = image.copy(Bitmap.Config.ARGB_8888, true);
|
||||
this.inputImage = rgbaImage;
|
||||
this.inputImage = image.copy(Bitmap.Config.ARGB_8888, true);
|
||||
}
|
||||
|
||||
private ArrayList<OcrResultModel> postprocess(ArrayList<OcrResultModel> results) {
|
||||
|
|
@ -319,7 +323,7 @@ public class Predictor {
|
|||
for (Point p : result.getPoints()) {
|
||||
sb.append("(").append(p.x).append(",").append(p.y).append(") ");
|
||||
}
|
||||
Log.i(TAG, sb.toString());
|
||||
Log.i(TAG, sb.toString()); // show LOG in Logcat panel
|
||||
outputResultSb.append(i + 1).append(": ").append(result.getLabel()).append("\n");
|
||||
}
|
||||
outputResult = outputResultSb.toString();
|
||||
|
|
|
|||
|
|
@ -5,7 +5,8 @@ import android.os.Bundle;
|
|||
import android.preference.CheckBoxPreference;
|
||||
import android.preference.EditTextPreference;
|
||||
import android.preference.ListPreference;
|
||||
import android.support.v7.app.ActionBar;
|
||||
|
||||
import androidx.appcompat.app.ActionBar;
|
||||
|
||||
import java.util.ArrayList;
|
||||
import java.util.List;
|
||||
|
|
|
|||
|
|
@ -2,6 +2,8 @@ package com.baidu.paddle.lite.demo.ocr;
|
|||
|
||||
import android.content.Context;
|
||||
import android.graphics.Bitmap;
|
||||
import android.graphics.Matrix;
|
||||
import android.media.ExifInterface;
|
||||
import android.os.Environment;
|
||||
|
||||
import java.io.*;
|
||||
|
|
@ -110,4 +112,48 @@ public class Utils {
|
|||
}
|
||||
return Bitmap.createScaledBitmap(bitmap, newWidth, newHeight, true);
|
||||
}
|
||||
|
||||
public static Bitmap rotateBitmap(Bitmap bitmap, int orientation) {
|
||||
|
||||
Matrix matrix = new Matrix();
|
||||
switch (orientation) {
|
||||
case ExifInterface.ORIENTATION_NORMAL:
|
||||
return bitmap;
|
||||
case ExifInterface.ORIENTATION_FLIP_HORIZONTAL:
|
||||
matrix.setScale(-1, 1);
|
||||
break;
|
||||
case ExifInterface.ORIENTATION_ROTATE_180:
|
||||
matrix.setRotate(180);
|
||||
break;
|
||||
case ExifInterface.ORIENTATION_FLIP_VERTICAL:
|
||||
matrix.setRotate(180);
|
||||
matrix.postScale(-1, 1);
|
||||
break;
|
||||
case ExifInterface.ORIENTATION_TRANSPOSE:
|
||||
matrix.setRotate(90);
|
||||
matrix.postScale(-1, 1);
|
||||
break;
|
||||
case ExifInterface.ORIENTATION_ROTATE_90:
|
||||
matrix.setRotate(90);
|
||||
break;
|
||||
case ExifInterface.ORIENTATION_TRANSVERSE:
|
||||
matrix.setRotate(-90);
|
||||
matrix.postScale(-1, 1);
|
||||
break;
|
||||
case ExifInterface.ORIENTATION_ROTATE_270:
|
||||
matrix.setRotate(-90);
|
||||
break;
|
||||
default:
|
||||
return bitmap;
|
||||
}
|
||||
try {
|
||||
Bitmap bmRotated = Bitmap.createBitmap(bitmap, 0, 0, bitmap.getWidth(), bitmap.getHeight(), matrix, true);
|
||||
bitmap.recycle();
|
||||
return bmRotated;
|
||||
}
|
||||
catch (OutOfMemoryError e) {
|
||||
e.printStackTrace();
|
||||
return null;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
|
|
|||
|
|
@ -1,5 +1,5 @@
|
|||
<?xml version="1.0" encoding="utf-8"?>
|
||||
<android.support.constraint.ConstraintLayout xmlns:android="http://schemas.android.com/apk/res/android"
|
||||
<androidx.constraintlayout.widget.ConstraintLayout xmlns:android="http://schemas.android.com/apk/res/android"
|
||||
xmlns:app="http://schemas.android.com/apk/res-auto"
|
||||
xmlns:tools="http://schemas.android.com/tools"
|
||||
android:layout_width="match_parent"
|
||||
|
|
@ -96,4 +96,4 @@
|
|||
|
||||
</RelativeLayout>
|
||||
|
||||
</android.support.constraint.ConstraintLayout>
|
||||
</androidx.constraintlayout.widget.ConstraintLayout>
|
||||
|
|
@ -0,0 +1,46 @@
|
|||
<?xml version="1.0" encoding="utf-8"?>
|
||||
<!-- for MiniActivity Use Only -->
|
||||
<androidx.constraintlayout.widget.ConstraintLayout xmlns:android="http://schemas.android.com/apk/res/android"
|
||||
xmlns:app="http://schemas.android.com/apk/res-auto"
|
||||
xmlns:tools="http://schemas.android.com/tools"
|
||||
android:layout_width="match_parent"
|
||||
android:layout_height="match_parent"
|
||||
app:layout_constraintLeft_toLeftOf="parent"
|
||||
app:layout_constraintLeft_toRightOf="parent"
|
||||
tools:context=".MainActivity">
|
||||
|
||||
<TextView
|
||||
android:id="@+id/sample_text"
|
||||
android:layout_width="0dp"
|
||||
android:layout_height="wrap_content"
|
||||
android:text="Hello World!"
|
||||
app:layout_constraintLeft_toLeftOf="parent"
|
||||
app:layout_constraintRight_toRightOf="parent"
|
||||
app:layout_constraintTop_toBottomOf="@id/imageView"
|
||||
android:scrollbars="vertical"
|
||||
/>
|
||||
|
||||
<ImageView
|
||||
android:id="@+id/imageView"
|
||||
android:layout_width="wrap_content"
|
||||
android:layout_height="wrap_content"
|
||||
android:paddingTop="20dp"
|
||||
android:paddingBottom="20dp"
|
||||
app:layout_constraintBottom_toTopOf="@id/imageView"
|
||||
app:layout_constraintLeft_toLeftOf="parent"
|
||||
app:layout_constraintRight_toRightOf="parent"
|
||||
app:layout_constraintTop_toTopOf="parent"
|
||||
tools:srcCompat="@tools:sample/avatars" />
|
||||
|
||||
<Button
|
||||
android:id="@+id/button"
|
||||
android:layout_width="wrap_content"
|
||||
android:layout_height="wrap_content"
|
||||
android:layout_marginBottom="4dp"
|
||||
android:text="Button"
|
||||
app:layout_constraintBottom_toBottomOf="parent"
|
||||
app:layout_constraintLeft_toLeftOf="parent"
|
||||
app:layout_constraintRight_toRightOf="parent"
|
||||
tools:layout_editor_absoluteX="161dp" />
|
||||
|
||||
</androidx.constraintlayout.widget.ConstraintLayout>
|
||||
|
|
@ -0,0 +1,4 @@
|
|||
<?xml version="1.0" encoding="utf-8"?>
|
||||
<paths xmlns:android="http://schemas.android.com/apk/res/android">
|
||||
<external-files-path name="my_images" path="Pictures" />
|
||||
</paths>
|
||||
|
|
@ -1,8 +1,17 @@
|
|||
project(ocr_system CXX C)
|
||||
|
||||
option(WITH_MKL "Compile demo with MKL/OpenBlas support, default use MKL." ON)
|
||||
option(WITH_GPU "Compile demo with GPU/CPU, default use CPU." OFF)
|
||||
option(WITH_STATIC_LIB "Compile demo with static/shared library, default use static." ON)
|
||||
option(USE_TENSORRT "Compile demo with TensorRT." OFF)
|
||||
option(WITH_TENSORRT "Compile demo with TensorRT." OFF)
|
||||
|
||||
SET(PADDLE_LIB "" CACHE PATH "Location of libraries")
|
||||
SET(OPENCV_DIR "" CACHE PATH "Location of libraries")
|
||||
SET(CUDA_LIB "" CACHE PATH "Location of libraries")
|
||||
SET(CUDNN_LIB "" CACHE PATH "Location of libraries")
|
||||
SET(TENSORRT_DIR "" CACHE PATH "Compile demo with TensorRT")
|
||||
|
||||
set(DEMO_NAME "ocr_system")
|
||||
|
||||
|
||||
macro(safe_set_static_flag)
|
||||
|
|
@ -15,24 +24,60 @@ macro(safe_set_static_flag)
|
|||
endforeach(flag_var)
|
||||
endmacro()
|
||||
|
||||
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++11 -g -fpermissive")
|
||||
set(CMAKE_STATIC_LIBRARY_PREFIX "")
|
||||
message("flags" ${CMAKE_CXX_FLAGS})
|
||||
set(CMAKE_CXX_FLAGS_RELEASE "-O3")
|
||||
if (WITH_MKL)
|
||||
ADD_DEFINITIONS(-DUSE_MKL)
|
||||
endif()
|
||||
|
||||
if(NOT DEFINED PADDLE_LIB)
|
||||
message(FATAL_ERROR "please set PADDLE_LIB with -DPADDLE_LIB=/path/paddle/lib")
|
||||
endif()
|
||||
if(NOT DEFINED DEMO_NAME)
|
||||
message(FATAL_ERROR "please set DEMO_NAME with -DDEMO_NAME=demo_name")
|
||||
|
||||
if(NOT DEFINED OPENCV_DIR)
|
||||
message(FATAL_ERROR "please set OPENCV_DIR with -DOPENCV_DIR=/path/opencv")
|
||||
endif()
|
||||
|
||||
|
||||
set(OPENCV_DIR ${OPENCV_DIR})
|
||||
if (WIN32)
|
||||
include_directories("${PADDLE_LIB}/paddle/fluid/inference")
|
||||
include_directories("${PADDLE_LIB}/paddle/include")
|
||||
link_directories("${PADDLE_LIB}/paddle/fluid/inference")
|
||||
find_package(OpenCV REQUIRED PATHS ${OPENCV_DIR}/build/ NO_DEFAULT_PATH)
|
||||
|
||||
else ()
|
||||
find_package(OpenCV REQUIRED PATHS ${OPENCV_DIR}/share/OpenCV NO_DEFAULT_PATH)
|
||||
include_directories("${PADDLE_LIB}/paddle/include")
|
||||
link_directories("${PADDLE_LIB}/paddle/lib")
|
||||
endif ()
|
||||
include_directories(${OpenCV_INCLUDE_DIRS})
|
||||
|
||||
include_directories("${PADDLE_LIB}/paddle/include")
|
||||
if (WIN32)
|
||||
add_definitions("/DGOOGLE_GLOG_DLL_DECL=")
|
||||
set(CMAKE_C_FLAGS_DEBUG "${CMAKE_C_FLAGS_DEBUG} /bigobj /MTd")
|
||||
set(CMAKE_C_FLAGS_RELEASE "${CMAKE_C_FLAGS_RELEASE} /bigobj /MT")
|
||||
set(CMAKE_CXX_FLAGS_DEBUG "${CMAKE_CXX_FLAGS_DEBUG} /bigobj /MTd")
|
||||
set(CMAKE_CXX_FLAGS_RELEASE "${CMAKE_CXX_FLAGS_RELEASE} /bigobj /MT")
|
||||
if (WITH_STATIC_LIB)
|
||||
safe_set_static_flag()
|
||||
add_definitions(-DSTATIC_LIB)
|
||||
endif()
|
||||
else()
|
||||
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -g -o3 -std=c++11")
|
||||
set(CMAKE_STATIC_LIBRARY_PREFIX "")
|
||||
endif()
|
||||
message("flags" ${CMAKE_CXX_FLAGS})
|
||||
|
||||
|
||||
if (WITH_GPU)
|
||||
if (NOT DEFINED CUDA_LIB OR ${CUDA_LIB} STREQUAL "")
|
||||
message(FATAL_ERROR "please set CUDA_LIB with -DCUDA_LIB=/path/cuda-8.0/lib64")
|
||||
endif()
|
||||
if (NOT WIN32)
|
||||
if (NOT DEFINED CUDNN_LIB)
|
||||
message(FATAL_ERROR "please set CUDNN_LIB with -DCUDNN_LIB=/path/cudnn_v7.4/cuda/lib64")
|
||||
endif()
|
||||
endif(NOT WIN32)
|
||||
endif()
|
||||
|
||||
include_directories("${PADDLE_LIB}/third_party/install/protobuf/include")
|
||||
include_directories("${PADDLE_LIB}/third_party/install/glog/include")
|
||||
include_directories("${PADDLE_LIB}/third_party/install/gflags/include")
|
||||
|
|
@ -43,10 +88,12 @@ include_directories("${PADDLE_LIB}/third_party/eigen3")
|
|||
|
||||
include_directories("${CMAKE_SOURCE_DIR}/")
|
||||
|
||||
if (USE_TENSORRT AND WITH_GPU)
|
||||
include_directories("${TENSORRT_ROOT}/include")
|
||||
link_directories("${TENSORRT_ROOT}/lib")
|
||||
if (NOT WIN32)
|
||||
if (WITH_TENSORRT AND WITH_GPU)
|
||||
include_directories("${TENSORRT_DIR}/include")
|
||||
link_directories("${TENSORRT_DIR}/lib")
|
||||
endif()
|
||||
endif(NOT WIN32)
|
||||
|
||||
link_directories("${PADDLE_LIB}/third_party/install/zlib/lib")
|
||||
|
||||
|
|
@ -57,18 +104,25 @@ link_directories("${PADDLE_LIB}/third_party/install/xxhash/lib")
|
|||
link_directories("${PADDLE_LIB}/paddle/lib")
|
||||
|
||||
|
||||
AUX_SOURCE_DIRECTORY(./src SRCS)
|
||||
add_executable(${DEMO_NAME} ${SRCS})
|
||||
|
||||
if(WITH_MKL)
|
||||
include_directories("${PADDLE_LIB}/third_party/install/mklml/include")
|
||||
if (WIN32)
|
||||
set(MATH_LIB ${PADDLE_LIB}/third_party/install/mklml/lib/mklml.lib
|
||||
${PADDLE_LIB}/third_party/install/mklml/lib/libiomp5md.lib)
|
||||
else ()
|
||||
set(MATH_LIB ${PADDLE_LIB}/third_party/install/mklml/lib/libmklml_intel${CMAKE_SHARED_LIBRARY_SUFFIX}
|
||||
${PADDLE_LIB}/third_party/install/mklml/lib/libiomp5${CMAKE_SHARED_LIBRARY_SUFFIX})
|
||||
execute_process(COMMAND cp -r ${PADDLE_LIB}/third_party/install/mklml/lib/libmklml_intel${CMAKE_SHARED_LIBRARY_SUFFIX} /usr/lib)
|
||||
endif ()
|
||||
set(MKLDNN_PATH "${PADDLE_LIB}/third_party/install/mkldnn")
|
||||
if(EXISTS ${MKLDNN_PATH})
|
||||
include_directories("${MKLDNN_PATH}/include")
|
||||
if (WIN32)
|
||||
set(MKLDNN_LIB ${MKLDNN_PATH}/lib/mkldnn.lib)
|
||||
else ()
|
||||
set(MKLDNN_LIB ${MKLDNN_PATH}/lib/libmkldnn.so.0)
|
||||
endif ()
|
||||
endif()
|
||||
else()
|
||||
set(MATH_LIB ${PADDLE_LIB}/third_party/install/openblas/lib/libopenblas${CMAKE_STATIC_LIBRARY_SUFFIX})
|
||||
endif()
|
||||
|
|
@ -82,24 +136,66 @@ else()
|
|||
${PADDLE_LIB}/paddle/lib/libpaddle_fluid${CMAKE_SHARED_LIBRARY_SUFFIX})
|
||||
endif()
|
||||
|
||||
set(EXTERNAL_LIB "-lrt -ldl -lpthread -lm")
|
||||
|
||||
if (NOT WIN32)
|
||||
set(DEPS ${DEPS}
|
||||
${MATH_LIB} ${MKLDNN_LIB}
|
||||
glog gflags protobuf z xxhash
|
||||
${EXTERNAL_LIB} ${OpenCV_LIBS})
|
||||
)
|
||||
if(EXISTS "${PADDLE_LIB}/third_party/install/snappystream/lib")
|
||||
set(DEPS ${DEPS} snappystream)
|
||||
endif()
|
||||
if (EXISTS "${PADDLE_LIB}/third_party/install/snappy/lib")
|
||||
set(DEPS ${DEPS} snappy)
|
||||
endif()
|
||||
else()
|
||||
set(DEPS ${DEPS}
|
||||
${MATH_LIB} ${MKLDNN_LIB}
|
||||
glog gflags_static libprotobuf xxhash)
|
||||
set(DEPS ${DEPS} libcmt shlwapi)
|
||||
if (EXISTS "${PADDLE_LIB}/third_party/install/snappy/lib")
|
||||
set(DEPS ${DEPS} snappy)
|
||||
endif()
|
||||
if(EXISTS "${PADDLE_LIB}/third_party/install/snappystream/lib")
|
||||
set(DEPS ${DEPS} snappystream)
|
||||
endif()
|
||||
endif(NOT WIN32)
|
||||
|
||||
|
||||
if(WITH_GPU)
|
||||
if (USE_TENSORRT)
|
||||
set(DEPS ${DEPS}
|
||||
${TENSORRT_ROOT}/lib/libnvinfer${CMAKE_SHARED_LIBRARY_SUFFIX})
|
||||
set(DEPS ${DEPS}
|
||||
${TENSORRT_ROOT}/lib/libnvinfer_plugin${CMAKE_SHARED_LIBRARY_SUFFIX})
|
||||
if(NOT WIN32)
|
||||
if (WITH_TENSORRT)
|
||||
set(DEPS ${DEPS} ${TENSORRT_DIR}/lib/libnvinfer${CMAKE_SHARED_LIBRARY_SUFFIX})
|
||||
set(DEPS ${DEPS} ${TENSORRT_DIR}/lib/libnvinfer_plugin${CMAKE_SHARED_LIBRARY_SUFFIX})
|
||||
endif()
|
||||
set(DEPS ${DEPS} ${CUDA_LIB}/libcudart${CMAKE_SHARED_LIBRARY_SUFFIX})
|
||||
set(DEPS ${DEPS} ${CUDA_LIB}/libcudart${CMAKE_SHARED_LIBRARY_SUFFIX} )
|
||||
set(DEPS ${DEPS} ${CUDA_LIB}/libcublas${CMAKE_SHARED_LIBRARY_SUFFIX} )
|
||||
set(DEPS ${DEPS} ${CUDNN_LIB}/libcudnn${CMAKE_SHARED_LIBRARY_SUFFIX})
|
||||
else()
|
||||
set(DEPS ${DEPS} ${CUDA_LIB}/cudart${CMAKE_STATIC_LIBRARY_SUFFIX} )
|
||||
set(DEPS ${DEPS} ${CUDA_LIB}/cublas${CMAKE_STATIC_LIBRARY_SUFFIX} )
|
||||
set(DEPS ${DEPS} ${CUDNN_LIB}/cudnn${CMAKE_STATIC_LIBRARY_SUFFIX})
|
||||
endif()
|
||||
endif()
|
||||
|
||||
|
||||
if (NOT WIN32)
|
||||
set(EXTERNAL_LIB "-ldl -lrt -lgomp -lz -lm -lpthread")
|
||||
set(DEPS ${DEPS} ${EXTERNAL_LIB})
|
||||
endif()
|
||||
|
||||
set(DEPS ${DEPS} ${OpenCV_LIBS})
|
||||
|
||||
AUX_SOURCE_DIRECTORY(./src SRCS)
|
||||
add_executable(${DEMO_NAME} ${SRCS})
|
||||
|
||||
target_link_libraries(${DEMO_NAME} ${DEPS})
|
||||
|
||||
if (WIN32 AND WITH_MKL)
|
||||
add_custom_command(TARGET ${DEMO_NAME} POST_BUILD
|
||||
COMMAND ${CMAKE_COMMAND} -E copy_if_different ${PADDLE_LIB}/third_party/install/mklml/lib/mklml.dll ./mklml.dll
|
||||
COMMAND ${CMAKE_COMMAND} -E copy_if_different ${PADDLE_LIB}/third_party/install/mklml/lib/libiomp5md.dll ./libiomp5md.dll
|
||||
COMMAND ${CMAKE_COMMAND} -E copy_if_different ${PADDLE_LIB}/third_party/install/mkldnn/lib/mkldnn.dll ./mkldnn.dll
|
||||
COMMAND ${CMAKE_COMMAND} -E copy_if_different ${PADDLE_LIB}/third_party/install/mklml/lib/mklml.dll ./release/mklml.dll
|
||||
COMMAND ${CMAKE_COMMAND} -E copy_if_different ${PADDLE_LIB}/third_party/install/mklml/lib/libiomp5md.dll ./release/libiomp5md.dll
|
||||
COMMAND ${CMAKE_COMMAND} -E copy_if_different ${PADDLE_LIB}/third_party/install/mkldnn/lib/mkldnn.dll ./release/mkldnn.dll
|
||||
)
|
||||
endif()
|
||||
|
|
@ -0,0 +1,95 @@
|
|||
# Visual Studio 2019 Community CMake 编译指南
|
||||
|
||||
PaddleOCR在Windows 平台下基于`Visual Studio 2019 Community` 进行了测试。微软从`Visual Studio 2017`开始即支持直接管理`CMake`跨平台编译项目,但是直到`2019`才提供了稳定和完全的支持,所以如果你想使用CMake管理项目编译构建,我们推荐你使用`Visual Studio 2019`环境下构建。
|
||||
|
||||
|
||||
## 前置条件
|
||||
* Visual Studio 2019
|
||||
* CUDA 9.0 / CUDA 10.0,cudnn 7+ (仅在使用GPU版本的预测库时需要)
|
||||
* CMake 3.0+
|
||||
|
||||
请确保系统已经安装好上述基本软件,我们使用的是`VS2019`的社区版。
|
||||
|
||||
**下面所有示例以工作目录为 `D:\projects`演示**。
|
||||
|
||||
### Step1: 下载PaddlePaddle C++ 预测库 fluid_inference
|
||||
|
||||
PaddlePaddle C++ 预测库针对不同的`CPU`和`CUDA`版本提供了不同的预编译版本,请根据实际情况下载: [C++预测库下载列表](https://www.paddlepaddle.org.cn/documentation/docs/zh/develop/advanced_guide/inference_deployment/inference/windows_cpp_inference.html)
|
||||
|
||||
解压后`D:\projects\fluid_inference`目录包含内容为:
|
||||
```
|
||||
fluid_inference
|
||||
├── paddle # paddle核心库和头文件
|
||||
|
|
||||
├── third_party # 第三方依赖库和头文件
|
||||
|
|
||||
└── version.txt # 版本和编译信息
|
||||
```
|
||||
|
||||
### Step2: 安装配置OpenCV
|
||||
|
||||
1. 在OpenCV官网下载适用于Windows平台的3.4.6版本, [下载地址](https://sourceforge.net/projects/opencvlibrary/files/3.4.6/opencv-3.4.6-vc14_vc15.exe/download)
|
||||
2. 运行下载的可执行文件,将OpenCV解压至指定目录,如`D:\projects\opencv`
|
||||
3. 配置环境变量,如下流程所示
|
||||
- 我的电脑->属性->高级系统设置->环境变量
|
||||
- 在系统变量中找到Path(如没有,自行创建),并双击编辑
|
||||
- 新建,将opencv路径填入并保存,如`D:\projects\opencv\build\x64\vc14\bin`
|
||||
|
||||
### Step3: 使用Visual Studio 2019直接编译CMake
|
||||
|
||||
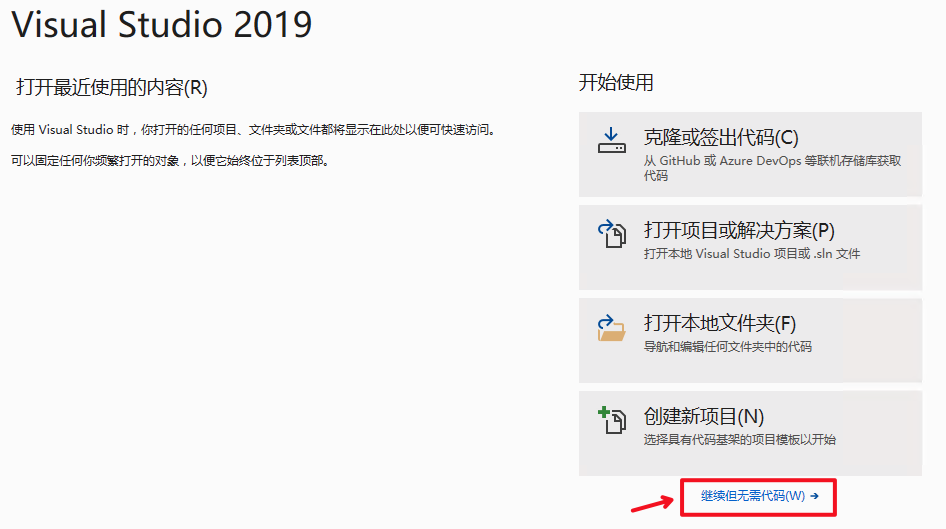
1. 打开Visual Studio 2019 Community,点击`继续但无需代码`
|
||||
|
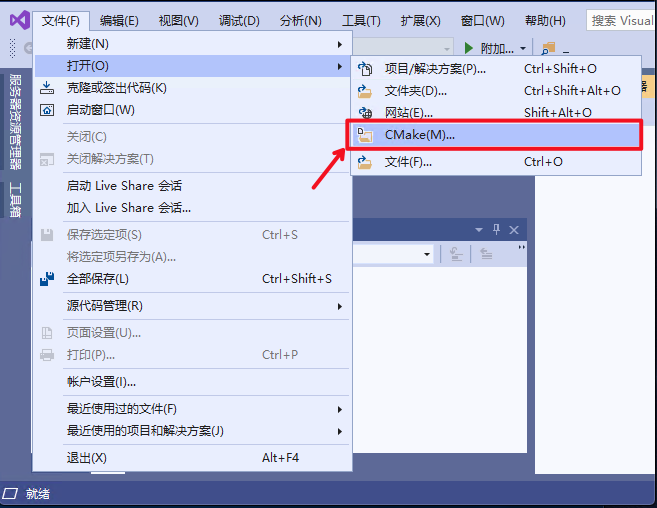
||||
2. 点击: `文件`->`打开`->`CMake`
|
||||
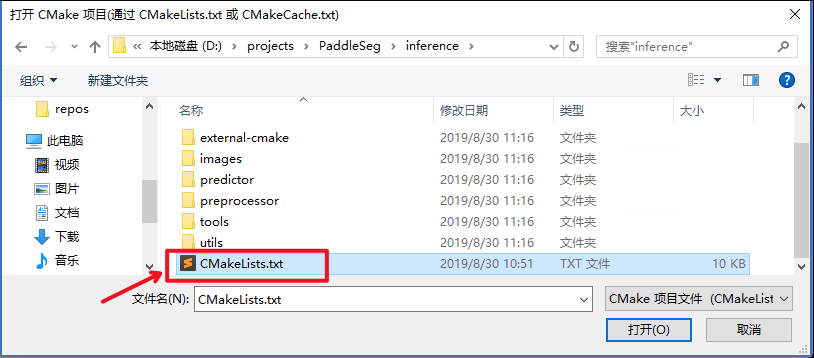
|
||||
|
||||
选择项目代码所在路径,并打开`CMakeList.txt`:
|
||||
|
||||
|
||||
|
||||
3. 点击:`项目`->`cpp_inference_demo的CMake设置`
|
||||
|
||||
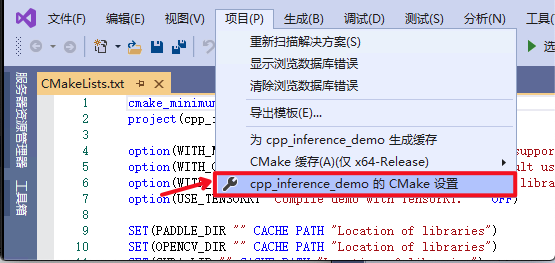
|
||||
|
||||
4. 点击`浏览`,分别设置编译选项指定`CUDA`、`CUDNN_LIB`、`OpenCV`、`Paddle预测库`的路径
|
||||
|
||||
三个编译参数的含义说明如下(带`*`表示仅在使用**GPU版本**预测库时指定, 其中CUDA库版本尽量对齐,**使用9.0、10.0版本,不使用9.2、10.1等版本CUDA库**):
|
||||
|
||||
| 参数名 | 含义 |
|
||||
| ---- | ---- |
|
||||
| *CUDA_LIB | CUDA的库路径 |
|
||||
| *CUDNN_LIB | CUDNN的库路径 |
|
||||
| OPENCV_DIR | OpenCV的安装路径 |
|
||||
| PADDLE_LIB | Paddle预测库的路径 |
|
||||
|
||||
**注意:**
|
||||
1. 使用`CPU`版预测库,请把`WITH_GPU`的勾去掉
|
||||
2. 如果使用的是`openblas`版本,请把`WITH_MKL`勾去掉
|
||||
|
||||
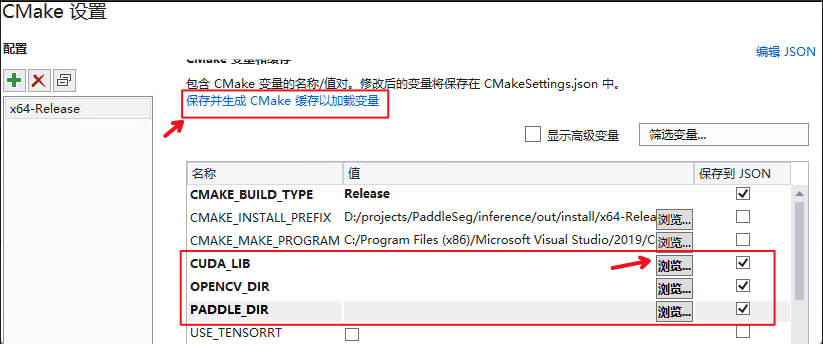
|
||||
|
||||
**设置完成后**, 点击上图中`保存并生成CMake缓存以加载变量`。
|
||||
|
||||
5. 点击`生成`->`全部生成`
|
||||
|
||||
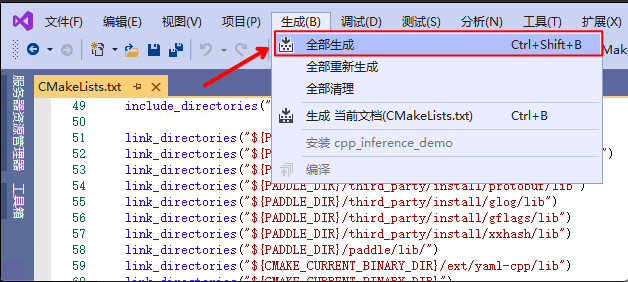
|
||||
|
||||
|
||||
### Step4: 预测及可视化
|
||||
|
||||
上述`Visual Studio 2019`编译产出的可执行文件在`out\build\x64-Release`目录下,打开`cmd`,并切换到该目录:
|
||||
|
||||
```
|
||||
cd D:\projects\PaddleOCR\deploy\cpp_infer\out\build\x64-Release
|
||||
```
|
||||
可执行文件`ocr_system.exe`即为样例的预测程序,其主要使用方法如下
|
||||
|
||||
```shell
|
||||
#预测图片 `D:\projects\PaddleOCR\doc\imgs\10.jpg`
|
||||
.\ocr_system.exe D:\projects\PaddleOCR\deploy\cpp_infer\tools\config.txt D:\projects\PaddleOCR\doc\imgs\10.jpg
|
||||
```
|
||||
|
||||
第一个参数为配置文件路径,第二个参数为需要预测的图片路径。
|
||||
|
||||
|
||||
### 注意
|
||||
* 在Windows下的终端中执行文件exe时,可能会发生乱码的现象,此时需要在终端中输入`CHCP 65001`,将终端的编码方式由GBK编码(默认)改为UTF-8编码,更加具体的解释可以参考这篇博客:[https://blog.csdn.net/qq_35038153/article/details/78430359](https://blog.csdn.net/qq_35038153/article/details/78430359)。
|
||||
|
|
@ -7,6 +7,9 @@
|
|||
|
||||
### 运行准备
|
||||
- Linux环境,推荐使用docker。
|
||||
- Windows环境,目前支持基于`Visual Studio 2019 Community`进行编译。
|
||||
|
||||
* 该文档主要介绍基于Linux环境的PaddleOCR C++预测流程,如果需要在Windows下基于预测库进行C++预测,具体编译方法请参考[Windows下编译教程](./docs/windows_vs2019_build.md)
|
||||
|
||||
### 1.1 编译opencv库
|
||||
|
||||
|
|
|
|||
|
|
@ -44,7 +44,7 @@ Config::LoadConfig(const std::string &config_path) {
|
|||
std::map<std::string, std::string> dict;
|
||||
for (int i = 0; i < config.size(); i++) {
|
||||
// pass for empty line or comment
|
||||
if (config[i].size() <= 1 or config[i][0] == '#') {
|
||||
if (config[i].size() <= 1 || config[i][0] == '#') {
|
||||
continue;
|
||||
}
|
||||
std::vector<std::string> res = split(config[i], " ");
|
||||
|
|
|
|||
|
|
@ -39,22 +39,21 @@ std::vector<std::string> Utility::ReadDict(const std::string &path) {
|
|||
void Utility::VisualizeBboxes(
|
||||
const cv::Mat &srcimg,
|
||||
const std::vector<std::vector<std::vector<int>>> &boxes) {
|
||||
cv::Point rook_points[boxes.size()][4];
|
||||
for (int n = 0; n < boxes.size(); n++) {
|
||||
for (int m = 0; m < boxes[0].size(); m++) {
|
||||
rook_points[n][m] = cv::Point(int(boxes[n][m][0]), int(boxes[n][m][1]));
|
||||
}
|
||||
}
|
||||
cv::Mat img_vis;
|
||||
srcimg.copyTo(img_vis);
|
||||
for (int n = 0; n < boxes.size(); n++) {
|
||||
const cv::Point *ppt[1] = {rook_points[n]};
|
||||
cv::Point rook_points[4];
|
||||
for (int m = 0; m < boxes[n].size(); m++) {
|
||||
rook_points[m] = cv::Point(int(boxes[n][m][0]), int(boxes[n][m][1]));
|
||||
}
|
||||
|
||||
const cv::Point *ppt[1] = {rook_points};
|
||||
int npt[] = {4};
|
||||
cv::polylines(img_vis, ppt, npt, 1, 1, CV_RGB(0, 255, 0), 2, 8, 0);
|
||||
}
|
||||
|
||||
cv::imwrite("./ocr_vis.png", img_vis);
|
||||
std::cout << "The detection visualized image saved in ./ocr_vis.png.pn"
|
||||
std::cout << "The detection visualized image saved in ./ocr_vis.png"
|
||||
<< std::endl;
|
||||
}
|
||||
|
||||
|
|
|
|||
|
|
@ -1,8 +1,7 @@
|
|||
|
||||
OPENCV_DIR=your_opencv_dir
|
||||
LIB_DIR=your_paddle_inference_dir
|
||||
CUDA_LIB_DIR=your_cuda_lib_dir
|
||||
CUDNN_LIB_DIR=/your_cudnn_lib_dir
|
||||
CUDNN_LIB_DIR=your_cudnn_lib_dir
|
||||
|
||||
BUILD_DIR=build
|
||||
rm -rf ${BUILD_DIR}
|
||||
|
|
@ -11,7 +10,6 @@ cd ${BUILD_DIR}
|
|||
cmake .. \
|
||||
-DPADDLE_LIB=${LIB_DIR} \
|
||||
-DWITH_MKL=ON \
|
||||
-DDEMO_NAME=ocr_system \
|
||||
-DWITH_GPU=OFF \
|
||||
-DWITH_STATIC_LIB=OFF \
|
||||
-DUSE_TENSORRT=OFF \
|
||||
|
|
|
|||
|
|
@ -15,8 +15,7 @@ det_model_dir ./inference/det_db
|
|||
# rec config
|
||||
rec_model_dir ./inference/rec_crnn
|
||||
char_list_file ../../ppocr/utils/ppocr_keys_v1.txt
|
||||
img_path ../../doc/imgs/11.jpg
|
||||
|
||||
# show the detection results
|
||||
visualize 0
|
||||
visualize 1
|
||||
|
||||
|
|
|
|||
|
|
@ -18,7 +18,7 @@ Paddle Lite是飞桨轻量化推理引擎,为手机、IOT端提供高效推理
|
|||
1. [Docker](https://paddle-lite.readthedocs.io/zh/latest/user_guides/source_compile.html#docker)
|
||||
2. [Linux](https://paddle-lite.readthedocs.io/zh/latest/user_guides/source_compile.html#android)
|
||||
3. [MAC OS](https://paddle-lite.readthedocs.io/zh/latest/user_guides/source_compile.html#id13)
|
||||
4. [Windows](https://paddle-lite.readthedocs.io/zh/latest/demo_guides/x86.html#windows)
|
||||
4. [Windows](https://paddle-lite.readthedocs.io/zh/latest/demo_guides/x86.html#id4)
|
||||
|
||||
### 1.2 准备预测库
|
||||
|
||||
|
|
@ -84,7 +84,7 @@ Paddle-Lite 提供了多种策略来自动优化原始的模型,其中包括
|
|||
|
||||
|模型简介|检测模型|识别模型|Paddle-Lite版本|
|
||||
|-|-|-|-|
|
||||
|超轻量级中文OCR opt优化模型|[下载地址](https://paddleocr.bj.bcebos.com/deploy/lite/ch_det_mv3_db_opt.nb)|[下载地址](https://paddleocr.bj.bcebos.com/deploy/lite/ch_rec_mv3_crnn_opt.nb)|2.6.1|
|
||||
|超轻量级中文OCR opt优化模型|[下载地址](https://paddleocr.bj.bcebos.com/deploy/lite/ch_det_mv3_db_opt.nb)|[下载地址](https://paddleocr.bj.bcebos.com/deploy/lite/ch_rec_mv3_crnn_opt.nb)|develop|
|
||||
|
||||
如果直接使用上述表格中的模型进行部署,可略过下述步骤,直接阅读 [2.2节](#2.2与手机联调)。
|
||||
|
||||
|
|
|
|||
|
|
@ -3,7 +3,7 @@
|
|||
|
||||
This tutorial will introduce how to use paddle-lite to deploy paddleOCR ultra-lightweight Chinese and English detection models on mobile phones.
|
||||
|
||||
addle Lite is a lightweight inference engine for PaddlePaddle.
|
||||
paddle-lite is a lightweight inference engine for PaddlePaddle.
|
||||
It provides efficient inference capabilities for mobile phones and IOTs,
|
||||
and extensively integrates cross-platform hardware to provide lightweight
|
||||
deployment solutions for end-side deployment issues.
|
||||
|
|
@ -17,7 +17,7 @@ deployment solutions for end-side deployment issues.
|
|||
[build for Docker](https://paddle-lite.readthedocs.io/zh/latest/user_guides/source_compile.html#docker)
|
||||
[build for Linux](https://paddle-lite.readthedocs.io/zh/latest/user_guides/source_compile.html#android)
|
||||
[build for MAC OS](https://paddle-lite.readthedocs.io/zh/latest/user_guides/source_compile.html#id13)
|
||||
[build for windows](https://paddle-lite.readthedocs.io/zh/latest/demo_guides/x86.html#windows)
|
||||
[build for windows](https://paddle-lite.readthedocs.io/zh/latest/demo_guides/x86.html#id4)
|
||||
|
||||
## 3. Download prebuild library for android and ios
|
||||
|
||||
|
|
@ -155,7 +155,7 @@ demo/cxx/ocr/
|
|||
|-- debug/
|
||||
| |--ch_det_mv3_db_opt.nb Detection model
|
||||
| |--ch_rec_mv3_crnn_opt.nb Recognition model
|
||||
| |--11.jpg image for OCR
|
||||
| |--11.jpg Image for OCR
|
||||
| |--ppocr_keys_v1.txt Dictionary file
|
||||
| |--libpaddle_light_api_shared.so C++ .so file
|
||||
| |--config.txt Config file
|
||||
|
|
|
|||
|
|
@ -0,0 +1,77 @@
|
|||
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from paddle_serving_client import Client
|
||||
import cv2
|
||||
import sys
|
||||
import numpy as np
|
||||
import os
|
||||
from paddle_serving_client import Client
|
||||
from paddle_serving_app.reader import Sequential, ResizeByFactor
|
||||
from paddle_serving_app.reader import Div, Normalize, Transpose
|
||||
from paddle_serving_app.reader import DBPostProcess, FilterBoxes
|
||||
if sys.argv[1] == 'gpu':
|
||||
from paddle_serving_server_gpu.web_service import WebService
|
||||
elif sys.argv[1] == 'cpu'
|
||||
from paddle_serving_server.web_service import WebService
|
||||
import time
|
||||
import re
|
||||
import base64
|
||||
|
||||
|
||||
class OCRService(WebService):
|
||||
def init_det(self):
|
||||
self.det_preprocess = Sequential([
|
||||
ResizeByFactor(32, 960), Div(255),
|
||||
Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]), Transpose(
|
||||
(2, 0, 1))
|
||||
])
|
||||
self.filter_func = FilterBoxes(10, 10)
|
||||
self.post_func = DBPostProcess({
|
||||
"thresh": 0.3,
|
||||
"box_thresh": 0.5,
|
||||
"max_candidates": 1000,
|
||||
"unclip_ratio": 1.5,
|
||||
"min_size": 3
|
||||
})
|
||||
|
||||
def preprocess(self, feed=[], fetch=[]):
|
||||
data = base64.b64decode(feed[0]["image"].encode('utf8'))
|
||||
data = np.fromstring(data, np.uint8)
|
||||
im = cv2.imdecode(data, cv2.IMREAD_COLOR)
|
||||
self.ori_h, self.ori_w, _ = im.shape
|
||||
det_img = self.det_preprocess(im)
|
||||
_, self.new_h, self.new_w = det_img.shape
|
||||
return {"image": det_img[np.newaxis, :].copy()}, ["concat_1.tmp_0"]
|
||||
|
||||
def postprocess(self, feed={}, fetch=[], fetch_map=None):
|
||||
det_out = fetch_map["concat_1.tmp_0"]
|
||||
ratio_list = [
|
||||
float(self.new_h) / self.ori_h, float(self.new_w) / self.ori_w
|
||||
]
|
||||
dt_boxes_list = self.post_func(det_out, [ratio_list])
|
||||
dt_boxes = self.filter_func(dt_boxes_list[0], [self.ori_h, self.ori_w])
|
||||
return {"dt_boxes": dt_boxes.tolist()}
|
||||
|
||||
|
||||
ocr_service = OCRService(name="ocr")
|
||||
ocr_service.load_model_config("ocr_det_model")
|
||||
if sys.argv[1] == 'gpu':
|
||||
ocr_service.set_gpus("0")
|
||||
ocr_service.prepare_server(workdir="workdir", port=9292, device="gpu", gpuid=0)
|
||||
elif sys.argv[1] == 'cpu':
|
||||
ocr_service.prepare_server(workdir="workdir", port=9292)
|
||||
ocr_service.init_det()
|
||||
ocr_service.run_debugger_service()
|
||||
ocr_service.run_web_service()
|
||||
|
|
@ -0,0 +1,78 @@
|
|||
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from paddle_serving_client import Client
|
||||
import cv2
|
||||
import sys
|
||||
import numpy as np
|
||||
import os
|
||||
from paddle_serving_client import Client
|
||||
from paddle_serving_app.reader import Sequential, ResizeByFactor
|
||||
from paddle_serving_app.reader import Div, Normalize, Transpose
|
||||
from paddle_serving_app.reader import DBPostProcess, FilterBoxes
|
||||
if sys.argv[1] == 'gpu':
|
||||
from paddle_serving_server_gpu.web_service import WebService
|
||||
elif sys.argv[1] == 'cpu':
|
||||
from paddle_serving_server.web_service import WebService
|
||||
import time
|
||||
import re
|
||||
import base64
|
||||
|
||||
|
||||
class OCRService(WebService):
|
||||
def init_det(self):
|
||||
self.det_preprocess = Sequential([
|
||||
ResizeByFactor(32, 960), Div(255),
|
||||
Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]), Transpose(
|
||||
(2, 0, 1))
|
||||
])
|
||||
self.filter_func = FilterBoxes(10, 10)
|
||||
self.post_func = DBPostProcess({
|
||||
"thresh": 0.3,
|
||||
"box_thresh": 0.5,
|
||||
"max_candidates": 1000,
|
||||
"unclip_ratio": 1.5,
|
||||
"min_size": 3
|
||||
})
|
||||
|
||||
def preprocess(self, feed=[], fetch=[]):
|
||||
data = base64.b64decode(feed[0]["image"].encode('utf8'))
|
||||
data = np.fromstring(data, np.uint8)
|
||||
im = cv2.imdecode(data, cv2.IMREAD_COLOR)
|
||||
self.ori_h, self.ori_w, _ = im.shape
|
||||
det_img = self.det_preprocess(im)
|
||||
_, self.new_h, self.new_w = det_img.shape
|
||||
print(det_img)
|
||||
return {"image": det_img}, ["concat_1.tmp_0"]
|
||||
|
||||
def postprocess(self, feed={}, fetch=[], fetch_map=None):
|
||||
det_out = fetch_map["concat_1.tmp_0"]
|
||||
ratio_list = [
|
||||
float(self.new_h) / self.ori_h, float(self.new_w) / self.ori_w
|
||||
]
|
||||
dt_boxes_list = self.post_func(det_out, [ratio_list])
|
||||
dt_boxes = self.filter_func(dt_boxes_list[0], [self.ori_h, self.ori_w])
|
||||
return {"dt_boxes": dt_boxes.tolist()}
|
||||
|
||||
|
||||
ocr_service = OCRService(name="ocr")
|
||||
ocr_service.load_model_config("ocr_det_model")
|
||||
if sys.argv[1] == 'gpu':
|
||||
ocr_service.set_gpus("0")
|
||||
ocr_service.prepare_server(workdir="workdir", port=9292, device="gpu", gpuid=0)
|
||||
elif sys.argv[1] == 'cpu':
|
||||
ocr_service.prepare_server(workdir="workdir", port=9292, device="cpu")
|
||||
ocr_service.init_det()
|
||||
ocr_service.run_rpc_service()
|
||||
ocr_service.run_web_service()
|
||||
|
|
@ -0,0 +1,113 @@
|
|||
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from paddle_serving_client import Client
|
||||
from paddle_serving_app.reader import OCRReader
|
||||
import cv2
|
||||
import sys
|
||||
import numpy as np
|
||||
import os
|
||||
from paddle_serving_client import Client
|
||||
from paddle_serving_app.reader import Sequential, URL2Image, ResizeByFactor
|
||||
from paddle_serving_app.reader import Div, Normalize, Transpose
|
||||
from paddle_serving_app.reader import DBPostProcess, FilterBoxes, GetRotateCropImage, SortedBoxes
|
||||
if sys.argv[1] == 'gpu':
|
||||
from paddle_serving_server_gpu.web_service import WebService
|
||||
elif sys.argv[1] == 'cpu':
|
||||
from paddle_serving_server.web_service import WebService
|
||||
from paddle_serving_app.local_predict import Debugger
|
||||
import time
|
||||
import re
|
||||
import base64
|
||||
|
||||
|
||||
class OCRService(WebService):
|
||||
def init_det_debugger(self, det_model_config):
|
||||
self.det_preprocess = Sequential([
|
||||
ResizeByFactor(32, 960), Div(255),
|
||||
Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]), Transpose(
|
||||
(2, 0, 1))
|
||||
])
|
||||
self.det_client = Debugger()
|
||||
if sys.argv[1] == 'gpu':
|
||||
self.det_client.load_model_config(
|
||||
det_model_config, gpu=True, profile=False)
|
||||
elif sys.argv[1] == 'cpu':
|
||||
self.det_client.load_model_config(
|
||||
det_model_config, gpu=False, profile=False)
|
||||
self.ocr_reader = OCRReader()
|
||||
|
||||
def preprocess(self, feed=[], fetch=[]):
|
||||
data = base64.b64decode(feed[0]["image"].encode('utf8'))
|
||||
data = np.fromstring(data, np.uint8)
|
||||
im = cv2.imdecode(data, cv2.IMREAD_COLOR)
|
||||
ori_h, ori_w, _ = im.shape
|
||||
det_img = self.det_preprocess(im)
|
||||
_, new_h, new_w = det_img.shape
|
||||
det_img = det_img[np.newaxis, :]
|
||||
det_img = det_img.copy()
|
||||
det_out = self.det_client.predict(
|
||||
feed={"image": det_img}, fetch=["concat_1.tmp_0"])
|
||||
filter_func = FilterBoxes(10, 10)
|
||||
post_func = DBPostProcess({
|
||||
"thresh": 0.3,
|
||||
"box_thresh": 0.5,
|
||||
"max_candidates": 1000,
|
||||
"unclip_ratio": 1.5,
|
||||
"min_size": 3
|
||||
})
|
||||
sorted_boxes = SortedBoxes()
|
||||
ratio_list = [float(new_h) / ori_h, float(new_w) / ori_w]
|
||||
dt_boxes_list = post_func(det_out["concat_1.tmp_0"], [ratio_list])
|
||||
dt_boxes = filter_func(dt_boxes_list[0], [ori_h, ori_w])
|
||||
dt_boxes = sorted_boxes(dt_boxes)
|
||||
get_rotate_crop_image = GetRotateCropImage()
|
||||
img_list = []
|
||||
max_wh_ratio = 0
|
||||
for i, dtbox in enumerate(dt_boxes):
|
||||
boximg = get_rotate_crop_image(im, dt_boxes[i])
|
||||
img_list.append(boximg)
|
||||
h, w = boximg.shape[0:2]
|
||||
wh_ratio = w * 1.0 / h
|
||||
max_wh_ratio = max(max_wh_ratio, wh_ratio)
|
||||
if len(img_list) == 0:
|
||||
return [], []
|
||||
_, w, h = self.ocr_reader.resize_norm_img(img_list[0],
|
||||
max_wh_ratio).shape
|
||||
imgs = np.zeros((len(img_list), 3, w, h)).astype('float32')
|
||||
for id, img in enumerate(img_list):
|
||||
norm_img = self.ocr_reader.resize_norm_img(img, max_wh_ratio)
|
||||
imgs[id] = norm_img
|
||||
feed = {"image": imgs.copy()}
|
||||
fetch = ["ctc_greedy_decoder_0.tmp_0", "softmax_0.tmp_0"]
|
||||
return feed, fetch
|
||||
|
||||
def postprocess(self, feed={}, fetch=[], fetch_map=None):
|
||||
rec_res = self.ocr_reader.postprocess(fetch_map, with_score=True)
|
||||
res_lst = []
|
||||
for res in rec_res:
|
||||
res_lst.append(res[0])
|
||||
res = {"res": res_lst}
|
||||
return res
|
||||
|
||||
|
||||
ocr_service = OCRService(name="ocr")
|
||||
ocr_service.load_model_config("ocr_rec_model")
|
||||
ocr_service.prepare_server(workdir="workdir", port=9292)
|
||||
ocr_service.init_det_debugger(det_model_config="ocr_det_model")
|
||||
if sys.argv[1] == 'gpu':
|
||||
ocr_service.run_debugger_service(gpu=True)
|
||||
elif sys.argv[1] == 'cpu':
|
||||
ocr_service.run_debugger_service()
|
||||
ocr_service.run_web_service()
|
||||
|
|
@ -0,0 +1,37 @@
|
|||
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
import requests
|
||||
import json
|
||||
import cv2
|
||||
import base64
|
||||
import os, sys
|
||||
import time
|
||||
|
||||
def cv2_to_base64(image):
|
||||
#data = cv2.imencode('.jpg', image)[1]
|
||||
return base64.b64encode(image).decode(
|
||||
'utf8') #data.tostring()).decode('utf8')
|
||||
|
||||
headers = {"Content-type": "application/json"}
|
||||
url = "http://127.0.0.1:9292/ocr/prediction"
|
||||
test_img_dir = "../../doc/imgs/"
|
||||
for img_file in os.listdir(test_img_dir):
|
||||
with open(os.path.join(test_img_dir, img_file), 'rb') as file:
|
||||
image_data1 = file.read()
|
||||
image = cv2_to_base64(image_data1)
|
||||
data = {"feed": [{"image": image}], "fetch": ["res"]}
|
||||
r = requests.post(url=url, headers=headers, data=json.dumps(data))
|
||||
print(r.json())
|
||||
|
|
@ -0,0 +1,105 @@
|
|||
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from paddle_serving_client import Client
|
||||
from paddle_serving_app.reader import OCRReader
|
||||
import cv2
|
||||
import sys
|
||||
import numpy as np
|
||||
import os
|
||||
from paddle_serving_client import Client
|
||||
from paddle_serving_app.reader import Sequential, URL2Image, ResizeByFactor
|
||||
from paddle_serving_app.reader import Div, Normalize, Transpose
|
||||
from paddle_serving_app.reader import DBPostProcess, FilterBoxes, GetRotateCropImage, SortedBoxes
|
||||
if sys.argv[1] == 'gpu':
|
||||
from paddle_serving_server_gpu.web_service import WebService
|
||||
elif sys.argv[1] == 'cpu':
|
||||
from paddle_serving_server.web_service import WebService
|
||||
import time
|
||||
import re
|
||||
import base64
|
||||
|
||||
|
||||
class OCRService(WebService):
|
||||
def init_det_client(self, det_port, det_client_config):
|
||||
self.det_preprocess = Sequential([
|
||||
ResizeByFactor(32, 960), Div(255),
|
||||
Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]), Transpose(
|
||||
(2, 0, 1))
|
||||
])
|
||||
self.det_client = Client()
|
||||
self.det_client.load_client_config(det_client_config)
|
||||
self.det_client.connect(["127.0.0.1:{}".format(det_port)])
|
||||
self.ocr_reader = OCRReader()
|
||||
|
||||
def preprocess(self, feed=[], fetch=[]):
|
||||
data = base64.b64decode(feed[0]["image"].encode('utf8'))
|
||||
data = np.fromstring(data, np.uint8)
|
||||
im = cv2.imdecode(data, cv2.IMREAD_COLOR)
|
||||
ori_h, ori_w, _ = im.shape
|
||||
det_img = self.det_preprocess(im)
|
||||
det_out = self.det_client.predict(
|
||||
feed={"image": det_img}, fetch=["concat_1.tmp_0"])
|
||||
_, new_h, new_w = det_img.shape
|
||||
filter_func = FilterBoxes(10, 10)
|
||||
post_func = DBPostProcess({
|
||||
"thresh": 0.3,
|
||||
"box_thresh": 0.5,
|
||||
"max_candidates": 1000,
|
||||
"unclip_ratio": 1.5,
|
||||
"min_size": 3
|
||||
})
|
||||
sorted_boxes = SortedBoxes()
|
||||
ratio_list = [float(new_h) / ori_h, float(new_w) / ori_w]
|
||||
dt_boxes_list = post_func(det_out["concat_1.tmp_0"], [ratio_list])
|
||||
dt_boxes = filter_func(dt_boxes_list[0], [ori_h, ori_w])
|
||||
dt_boxes = sorted_boxes(dt_boxes)
|
||||
get_rotate_crop_image = GetRotateCropImage()
|
||||
feed_list = []
|
||||
img_list = []
|
||||
max_wh_ratio = 0
|
||||
for i, dtbox in enumerate(dt_boxes):
|
||||
boximg = get_rotate_crop_image(im, dt_boxes[i])
|
||||
img_list.append(boximg)
|
||||
h, w = boximg.shape[0:2]
|
||||
wh_ratio = w * 1.0 / h
|
||||
max_wh_ratio = max(max_wh_ratio, wh_ratio)
|
||||
for img in img_list:
|
||||
norm_img = self.ocr_reader.resize_norm_img(img, max_wh_ratio)
|
||||
feed = {"image": norm_img}
|
||||
feed_list.append(feed)
|
||||
fetch = ["ctc_greedy_decoder_0.tmp_0", "softmax_0.tmp_0"]
|
||||
return feed_list, fetch
|
||||
|
||||
def postprocess(self, feed={}, fetch=[], fetch_map=None):
|
||||
rec_res = self.ocr_reader.postprocess(fetch_map, with_score=True)
|
||||
res_lst = []
|
||||
for res in rec_res:
|
||||
res_lst.append(res[0])
|
||||
res = {"res": res_lst}
|
||||
return res
|
||||
|
||||
|
||||
ocr_service = OCRService(name="ocr")
|
||||
ocr_service.load_model_config("ocr_rec_model")
|
||||
if sys.argv[1] == 'gpu':
|
||||
ocr_service.set_gpus("0")
|
||||
ocr_service.prepare_server(workdir="workdir", port=9292, device="gpu", gpuid=0)
|
||||
elif sys.argv[1] == 'cpu':
|
||||
ocr_service.prepare_server(workdir="workdir", port=9292)
|
||||
ocr_service.init_det_client(
|
||||
det_port=9293,
|
||||
det_client_config="ocr_det_client/serving_client_conf.prototxt")
|
||||
ocr_service.run_rpc_service()
|
||||
ocr_service.run_web_service()
|
||||
|
|
@ -1,28 +1,115 @@
|
|||
# Paddle Serving 服务部署
|
||||
# Paddle Serving 服务部署(Beta)
|
||||
|
||||
本教程将介绍基于[Paddle Serving](https://github.com/PaddlePaddle/Serving)部署在线预测服务的详细步骤。
|
||||
本教程将介绍基于[Paddle Serving](https://github.com/PaddlePaddle/Serving)部署PaddleOCR在线预测服务的详细步骤。
|
||||
|
||||
## 快速启动服务
|
||||
|
||||
### 1. 准备环境
|
||||
我们先安装Paddle Serving相关组件
|
||||
我们推荐用户使用GPU来做Paddle Serving的OCR服务部署
|
||||
|
||||
**CUDA版本:9.0**
|
||||
|
||||
**CUDNN版本:7.0**
|
||||
|
||||
**操作系统版本:CentOS 6以上**
|
||||
|
||||
**Python3操作指南:**
|
||||
```
|
||||
#以下提供beta版本的paddle serving whl包,欢迎试用,正式版会在8月中正式上线
|
||||
#GPU用户下载server包使用这个链接
|
||||
wget --no-check-certificate https://paddle-serving.bj.bcebos.com/others/paddle_serving_server_gpu-0.3.2-py3-none-any.whl
|
||||
python -m pip install paddle_serving_server_gpu-0.3.2-py3-none-any.whl
|
||||
#CPU版本使用这个链接
|
||||
wget --no-check-certificate https://paddle-serving.bj.bcebos.com/others/paddle_serving_server-0.3.2-py3-none-any.whl
|
||||
python -m pip install paddle_serving_server-0.3.2-py3-none-any.whl
|
||||
#客户端和App包使用以下链接(CPU,GPU通用)
|
||||
wget --no-check-certificate https://paddle-serving.bj.bcebos.com/others/paddle_serving_client-0.3.2-cp36-none-any.whl
|
||||
wget --no-check-certificate https://paddle-serving.bj.bcebos.com/others/paddle_serving_app-0.1.2-py3-none-any.whl
|
||||
python -m pip install paddle_serving_app-0.1.2-py3-none-any.whl paddle_serving_client-0.3.2-cp36-none-any.whl
|
||||
```
|
||||
|
||||
**Python2操作指南:**
|
||||
```
|
||||
#以下提供beta版本的paddle serving whl包,欢迎试用,正式版会在8月中正式上线
|
||||
#GPU用户下载server包使用这个链接
|
||||
wget --no-check-certificate https://paddle-serving.bj.bcebos.com/others/paddle_serving_server_gpu-0.3.2-py2-none-any.whl
|
||||
python -m pip install paddle_serving_server_gpu-0.3.2-py2-none-any.whl
|
||||
#CPU版本使用这个链接
|
||||
wget --no-check-certificate https://paddle-serving.bj.bcebos.com/others/paddle_serving_server-0.3.2-py2-none-any.whl
|
||||
python -m pip install paddle_serving_server-0.3.2-py2-none-any.whl
|
||||
|
||||
#客户端和App包使用以下链接(CPU,GPU通用)
|
||||
wget --no-check-certificate https://paddle-serving.bj.bcebos.com/others/paddle_serving_app-0.1.2-py2-none-any.whl
|
||||
wget --no-check-certificate https://paddle-serving.bj.bcebos.com/others/paddle_serving_client-0.3.2-cp27-none-any.whl
|
||||
python -m pip install paddle_serving_app-0.1.2-py2-none-any.whl paddle_serving_client-0.3.2-cp27-none-any.whl
|
||||
```
|
||||
|
||||
### 2. 模型转换
|
||||
可以使用`paddle_serving_app`提供的模型,执行下列命令
|
||||
```
|
||||
python -m paddle_serving_app.package --get_model ocr_rec
|
||||
tar -xzvf ocr_rec.tar.gz
|
||||
python -m paddle_serving_app.package --get_model ocr_det
|
||||
tar -xzvf ocr_det.tar.gz
|
||||
```
|
||||
执行上述命令会下载`db_crnn_mobile`的模型,如果想要下载规模更大的`db_crnn_server`模型,可以在下载预测模型并解压之后。参考[如何从Paddle保存的预测模型转为Paddle Serving格式可部署的模型](https://github.com/PaddlePaddle/Serving/blob/develop/doc/INFERENCE_TO_SERVING_CN.md)。
|
||||
|
||||
### 3. 启动服务
|
||||
启动服务可以根据实际需求选择启动`标准版`或者`快速版`,两种方式的对比如下表:
|
||||
|
||||
|版本|特点|适用场景|
|
||||
|-|-|-|
|
||||
|标准版|||
|
||||
|快速版|||
|
||||
|标准版|稳定性高,分布式部署|适用于吞吐量大,需要跨机房部署的情况|
|
||||
|快速版|部署方便,预测速度快|适用于对预测速度要求高,迭代速度快的场景|
|
||||
|
||||
#### 方式1. 启动标准版服务
|
||||
|
||||
```
|
||||
# cpu,gpu启动二选一,以下是cpu启动
|
||||
python -m paddle_serving_server.serve --model ocr_det_model --port 9293
|
||||
python ocr_web_server.py cpu
|
||||
# gpu启动
|
||||
python -m paddle_serving_server_gpu.serve --model ocr_det_model --port 9293 --gpu_id 0
|
||||
python ocr_web_server.py gpu
|
||||
```
|
||||
|
||||
#### 方式2. 启动快速版服务
|
||||
|
||||
```
|
||||
# cpu,gpu启动二选一,以下是cpu启动
|
||||
python ocr_local_server.py cpu
|
||||
# gpu启动
|
||||
python ocr_local_server.py gpu
|
||||
```
|
||||
|
||||
## 发送预测请求
|
||||
|
||||
```
|
||||
python ocr_web_client.py
|
||||
```
|
||||
|
||||
## 返回结果格式说明
|
||||
|
||||
返回结果是json格式
|
||||
```
|
||||
{u'result': {u'res': [u'\u571f\u5730\u6574\u6cbb\u4e0e\u571f\u58e4\u4fee\u590d\u7814\u7a76\u4e2d\u5fc3', u'\u534e\u5357\u519c\u4e1a\u5927\u5b661\u7d20\u56fe']}}
|
||||
```
|
||||
我们也可以打印结果json串中`res`字段的每一句话
|
||||
```
|
||||
土地整治与土壤修复研究中心
|
||||
华南农业大学1素图
|
||||
```
|
||||
|
||||
## 自定义修改服务逻辑
|
||||
|
||||
在`ocr_web_server.py`或是`ocr_local_server.py`当中的`preprocess`函数里面做了检测服务和识别服务的前处理,`postprocess`函数里面做了识别的后处理服务,可以在相应的函数中做修改。调用了`paddle_serving_app`库提供的常见CV模型的前处理/后处理库。
|
||||
|
||||
如果想要单独启动Paddle Serving的检测服务和识别服务,参见下列表格, 执行对应的脚本即可,并且在命令行参数注明用的CPU或是GPU来提供服务。
|
||||
|
||||
| 模型 | 标准版 | 快速版 |
|
||||
| ---- | ----------------- | ------------------- |
|
||||
| 检测 | det_web_server.py | det_local_server.py |
|
||||
| 识别 | rec_web_server.py | rec_local_server.py |
|
||||
|
||||
更多信息参见[Paddle Serving](https://github.com/PaddlePaddle/Serving)
|
||||
|
|
|
|||
|
|
@ -0,0 +1,72 @@
|
|||
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from paddle_serving_client import Client
|
||||
from paddle_serving_app.reader import OCRReader
|
||||
import cv2
|
||||
import sys
|
||||
import numpy as np
|
||||
import os
|
||||
from paddle_serving_client import Client
|
||||
from paddle_serving_app.reader import Sequential, URL2Image, ResizeByFactor
|
||||
from paddle_serving_app.reader import Div, Normalize, Transpose
|
||||
from paddle_serving_app.reader import DBPostProcess, FilterBoxes, GetRotateCropImage, SortedBoxes
|
||||
from paddle_serving_server_gpu.web_service import WebService
|
||||
import time
|
||||
import re
|
||||
import base64
|
||||
|
||||
|
||||
class OCRService(WebService):
|
||||
def init_rec(self):
|
||||
self.ocr_reader = OCRReader()
|
||||
|
||||
def preprocess(self, feed=[], fetch=[]):
|
||||
img_list = []
|
||||
for feed_data in feed:
|
||||
data = base64.b64decode(feed_data["image"].encode('utf8'))
|
||||
data = np.fromstring(data, np.uint8)
|
||||
im = cv2.imdecode(data, cv2.IMREAD_COLOR)
|
||||
img_list.append(im)
|
||||
max_wh_ratio = 0
|
||||
for i, boximg in enumerate(img_list):
|
||||
h, w = boximg.shape[0:2]
|
||||
wh_ratio = w * 1.0 / h
|
||||
max_wh_ratio = max(max_wh_ratio, wh_ratio)
|
||||
_, w, h = self.ocr_reader.resize_norm_img(img_list[0],
|
||||
max_wh_ratio).shape
|
||||
imgs = np.zeros((len(img_list), 3, w, h)).astype('float32')
|
||||
for i, img in enumerate(img_list):
|
||||
norm_img = self.ocr_reader.resize_norm_img(img, max_wh_ratio)
|
||||
imgs[i] = norm_img
|
||||
feed = {"image": imgs.copy()}
|
||||
fetch = ["ctc_greedy_decoder_0.tmp_0", "softmax_0.tmp_0"]
|
||||
return feed, fetch
|
||||
|
||||
def postprocess(self, feed={}, fetch=[], fetch_map=None):
|
||||
rec_res = self.ocr_reader.postprocess(fetch_map, with_score=True)
|
||||
res_lst = []
|
||||
for res in rec_res:
|
||||
res_lst.append(res[0])
|
||||
res = {"res": res_lst}
|
||||
return res
|
||||
|
||||
|
||||
ocr_service = OCRService(name="ocr")
|
||||
ocr_service.load_model_config("ocr_rec_model")
|
||||
ocr_service.set_gpus("0")
|
||||
ocr_service.init_rec()
|
||||
ocr_service.prepare_server(workdir="workdir", port=9292, device="gpu", gpuid=0)
|
||||
ocr_service.run_debugger_service()
|
||||
ocr_service.run_web_service()
|
||||
|
|
@ -0,0 +1,77 @@
|
|||
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from paddle_serving_client import Client
|
||||
from paddle_serving_app.reader import OCRReader
|
||||
import cv2
|
||||
import sys
|
||||
import numpy as np
|
||||
import os
|
||||
from paddle_serving_client import Client
|
||||
from paddle_serving_app.reader import Sequential, URL2Image, ResizeByFactor
|
||||
from paddle_serving_app.reader import Div, Normalize, Transpose
|
||||
from paddle_serving_app.reader import DBPostProcess, FilterBoxes, GetRotateCropImage, SortedBoxes
|
||||
if sys.argv[1] == 'gpu':
|
||||
from paddle_serving_server_gpu.web_service import WebService
|
||||
elif sys.argv[1] == 'cpu':
|
||||
from paddle_serving_server.web_service import WebService
|
||||
import time
|
||||
import re
|
||||
import base64
|
||||
|
||||
|
||||
class OCRService(WebService):
|
||||
def init_rec(self):
|
||||
self.ocr_reader = OCRReader()
|
||||
|
||||
def preprocess(self, feed=[], fetch=[]):
|
||||
# TODO: to handle batch rec images
|
||||
img_list = []
|
||||
for feed_data in feed:
|
||||
data = base64.b64decode(feed_data["image"].encode('utf8'))
|
||||
data = np.fromstring(data, np.uint8)
|
||||
im = cv2.imdecode(data, cv2.IMREAD_COLOR)
|
||||
img_list.append(im)
|
||||
feed_list = []
|
||||
max_wh_ratio = 0
|
||||
for i, boximg in enumerate(img_list):
|
||||
h, w = boximg.shape[0:2]
|
||||
wh_ratio = w * 1.0 / h
|
||||
max_wh_ratio = max(max_wh_ratio, wh_ratio)
|
||||
for img in img_list:
|
||||
norm_img = self.ocr_reader.resize_norm_img(img, max_wh_ratio)
|
||||
feed = {"image": norm_img}
|
||||
feed_list.append(feed)
|
||||
fetch = ["ctc_greedy_decoder_0.tmp_0", "softmax_0.tmp_0"]
|
||||
return feed_list, fetch
|
||||
|
||||
def postprocess(self, feed={}, fetch=[], fetch_map=None):
|
||||
rec_res = self.ocr_reader.postprocess(fetch_map, with_score=True)
|
||||
res_lst = []
|
||||
for res in rec_res:
|
||||
res_lst.append(res[0])
|
||||
res = {"res": res_lst}
|
||||
return res
|
||||
|
||||
|
||||
ocr_service = OCRService(name="ocr")
|
||||
ocr_service.load_model_config("ocr_rec_model")
|
||||
ocr_service.init_rec()
|
||||
if sys.argv[1] == 'gpu':
|
||||
ocr_service.set_gpus("0")
|
||||
ocr_service.prepare_server(workdir="workdir", port=9292, device="gpu", gpuid=0)
|
||||
elif sys.argv[1] == 'cpu':
|
||||
ocr_service.prepare_server(workdir="workdir", port=9292, device="cpu")
|
||||
ocr_service.run_rpc_service()
|
||||
ocr_service.run_web_service()
|
||||
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 13 KiB |
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 105 KiB |
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 185 KiB |
|
|
@ -0,0 +1,57 @@
|
|||
# Android Demo 快速测试
|
||||
|
||||
|
||||
### 1. 安装最新版本的Android Studio
|
||||
|
||||
可以从 https://developer.android.com/studio 下载。本Demo使用是4.0版本Android Studio编写。
|
||||
|
||||
### 2. 创建新项目
|
||||
|
||||
Demo测试的时候使用的是NDK 20b版本,20版本以上均可以支持编译成功。
|
||||
|
||||
如果您是初学者,可以用以下方式安装和测试NDK编译环境。
|
||||
点击 File -> New ->New Project, 新建 "Native C++" project
|
||||
|
||||
|
||||
1. Start a new Android Studio project
|
||||
在项目模版中选择 Native C++ 选择PaddleOCR/depoly/android_demo 路径
|
||||
进入项目后会自动编译,第一次编译会花费较长的时间,建议添加代理加速下载。
|
||||
|
||||
**代理添加:**
|
||||
|
||||
选择 Android Studio -> Perferences -> Appearance & Behavior -> System Settings -> HTTP Proxy -> Manual proxy configuration
|
||||
|
||||

|
||||
|
||||
2. 开始编译
|
||||
|
||||
点击编译按钮,连接手机,跟着Android Studio的引导完成操作。
|
||||
|
||||
在 Android Studio 里看到下图,表示编译完成:
|
||||
|
||||

|
||||
|
||||
**提示:** 此时如果出现下列找不到OpenCV的报错信息,请重新点击编译,编译完成后退出项目,再次进入。
|
||||
|
||||

|
||||
|
||||
### 3. 发送到手机端
|
||||
|
||||
完成编译,点击运行,在手机端查看效果。
|
||||
|
||||
### 4. 如何自定义demo图片
|
||||
|
||||
1. 图片存放路径:android_demo/app/src/main/assets/images
|
||||
|
||||
将自定义图片放置在该路径下
|
||||
|
||||
2. 配置文件: android_demo/app/src/main/res/values/strings.xml
|
||||
|
||||
修改 IMAGE_PATH_DEFAULT 为自定义图片名即可
|
||||
|
||||
|
||||
# 获得更多支持
|
||||
前往[端计算模型生成平台EasyEdge](https://ai.baidu.com/easyedge/app/open_source_demo?referrerUrl=paddlelite),获得更多开发支持:
|
||||
|
||||
- Demo APP:可使用手机扫码安装,方便手机端快速体验文字识别
|
||||
- SDK:模型被封装为适配不同芯片硬件和操作系统SDK,包括完善的接口,方便进行二次开发
|
||||
|
|
@ -60,6 +60,8 @@
|
|||
| beta1 | 设置一阶矩估计的指数衰减率 | 0.9 | \ |
|
||||
| beta2 | 设置二阶矩估计的指数衰减率 | 0.999 | \ |
|
||||
| decay | 是否使用decay | \ | \ |
|
||||
| function(decay) | 设置decay方式 | cosine_decay | 目前只支持cosin_decay |
|
||||
| step_each_epoch | 每个epoch包含多少次迭代 | 20 | 计算方式:total_image_num / (batch_size_per_card * card_size) |
|
||||
| total_epoch | 总共迭代多少个epoch | 1000 | 与Global.epoch_num 一致 |
|
||||
| function(decay) | 设置decay方式 | - | 目前支持cosine_decay与piecewise_decay |
|
||||
| step_each_epoch | 每个epoch包含多少次迭代, cosine_decay时有效 | 20 | 计算方式:total_image_num / (batch_size_per_card * card_size) |
|
||||
| total_epoch | 总共迭代多少个epoch, cosine_decay时有效 | 1000 | 与Global.epoch_num 一致 |
|
||||
| boundaries | 学习率下降时的迭代次数间隔, piecewise_decay时有效 | - | 参数为列表形式 |
|
||||
| decay_rate | 学习率衰减系数, piecewise_decay时有效 | - | \ |
|
||||
|
|
|
|||
|
|
@ -26,7 +26,7 @@ wget -P ./train_data/ https://paddleocr.bj.bcebos.com/dataset/test_icdar2015_la
|
|||
提供的标注文件格式为,其中中间是"\t"分隔:
|
||||
```
|
||||
" 图像文件名 json.dumps编码的图像标注信息"
|
||||
ch4_test_images/img_61.jpg [{"transcription": "MASA", "points": [[310, 104], [416, 141], [418, 216], [312, 179]], ...}]
|
||||
ch4_test_images/img_61.jpg [{"transcription": "MASA", "points": [[310, 104], [416, 141], [418, 216], [312, 179]]}, {...}]
|
||||
```
|
||||
json.dumps编码前的图像标注信息是包含多个字典的list,字典中的 `points` 表示文本框的四个点的坐标(x, y),从左上角的点开始顺时针排列。
|
||||
`transcription` 表示当前文本框的文字,在文本检测任务中并不需要这个信息。
|
||||
|
|
|
|||
|
|
@ -3,15 +3,15 @@
|
|||
经测试PaddleOCR可在glibc 2.23上运行,您也可以测试其他glibc版本或安装glic 2.23
|
||||
PaddleOCR 工作环境
|
||||
- PaddlePaddle 1.7+
|
||||
- python3
|
||||
- python3.7
|
||||
- glibc 2.23
|
||||
- cuDNN 7.6+ (GPU)
|
||||
|
||||
建议使用我们提供的docker运行PaddleOCR,有关docker使用请参考[链接](https://docs.docker.com/get-started/)。
|
||||
建议使用我们提供的docker运行PaddleOCR,有关docker、nvidia-docker使用请参考[链接](https://docs.docker.com/get-started/)。
|
||||
|
||||
*如您希望使用 mac 或 windows直接运行预测代码,可以从第2步开始执行。*
|
||||
|
||||
1. (建议)准备docker环境。第一次使用这个镜像,会自动下载该镜像,请耐心等待。
|
||||
**1. (建议)准备docker环境。第一次使用这个镜像,会自动下载该镜像,请耐心等待。**
|
||||
```
|
||||
# 切换到工作目录下
|
||||
cd /home/Projects
|
||||
|
|
@ -21,10 +21,10 @@ cd /home/Projects
|
|||
如果您希望在CPU环境下使用docker,使用docker而不是nvidia-docker创建docker
|
||||
sudo docker run --name ppocr -v $PWD:/paddle --network=host -it hub.baidubce.com/paddlepaddle/paddle:latest-gpu-cuda9.0-cudnn7-dev /bin/bash
|
||||
|
||||
如果您的机器安装的是CUDA9,请运行以下命令创建容器
|
||||
如果使用CUDA9,请运行以下命令创建容器
|
||||
sudo nvidia-docker run --name ppocr -v $PWD:/paddle --network=host -it hub.baidubce.com/paddlepaddle/paddle:latest-gpu-cuda9.0-cudnn7-dev /bin/bash
|
||||
|
||||
如果您的机器安装的是CUDA10,请运行以下命令创建容器
|
||||
如果使用CUDA10,请运行以下命令创建容器
|
||||
sudo nvidia-docker run --name ppocr -v $PWD:/paddle --network=host -it hub.baidubce.com/paddlepaddle/paddle:latest-gpu-cuda10.0-cudnn7-dev /bin/bash
|
||||
|
||||
您也可以访问[DockerHub](https://hub.docker.com/r/paddlepaddle/paddle/tags/)获取与您机器适配的镜像。
|
||||
|
|
@ -47,7 +47,7 @@ docker images
|
|||
hub.baidubce.com/paddlepaddle/paddle latest-gpu-cuda9.0-cudnn7-dev f56310dcc829
|
||||
```
|
||||
|
||||
2. 安装PaddlePaddle Fluid v1.7
|
||||
**2. 安装PaddlePaddle Fluid v1.7**
|
||||
```
|
||||
pip3 install --upgrade pip
|
||||
|
||||
|
|
@ -64,7 +64,7 @@ python3 -m pip install paddlepaddle==1.7.2 -i https://pypi.tuna.tsinghua.edu.cn/
|
|||
更多的版本需求,请参照[安装文档](https://www.paddlepaddle.org.cn/install/quick)中的说明进行操作。
|
||||
```
|
||||
|
||||
3. 克隆PaddleOCR repo代码
|
||||
**3. 克隆PaddleOCR repo代码**
|
||||
```
|
||||
【推荐】git clone https://github.com/PaddlePaddle/PaddleOCR
|
||||
|
||||
|
|
@ -75,8 +75,11 @@ git clone https://gitee.com/paddlepaddle/PaddleOCR
|
|||
注:码云托管代码可能无法实时同步本github项目更新,存在3~5天延时,请优先使用推荐方式。
|
||||
```
|
||||
|
||||
4. 安装第三方库
|
||||
**4. 安装第三方库**
|
||||
```
|
||||
cd PaddleOCR
|
||||
pip3 install -r requirments.txt
|
||||
```
|
||||
|
||||
注意,windows环境下,建议从[这里](https://www.lfd.uci.edu/~gohlke/pythonlibs/#shapely)下载shapely安装包完成安装,
|
||||
直接通过pip安装的shapely库可能出现`[winRrror 126] 找不到指定模块的问题`。
|
||||
|
|
|
|||
|
|
@ -21,12 +21,11 @@ ln -sf <path/to/dataset> <path/to/paddle_ocr>/train_data/dataset
|
|||
* 使用自己数据集:
|
||||
|
||||
若您希望使用自己的数据进行训练,请参考下文组织您的数据。
|
||||
|
||||
- 训练集
|
||||
|
||||
首先请将训练图片放入同一个文件夹(train_images),并用一个txt文件(rec_gt_train.txt)记录图片路径和标签。
|
||||
|
||||
* 注意: 默认请将图片路径和图片标签用 \t 分割,如用其他方式分割将造成训练报错
|
||||
**注意:** 默认请将图片路径和图片标签用 \t 分割,如用其他方式分割将造成训练报错
|
||||
|
||||
```
|
||||
" 图像文件名 图像标注信息 "
|
||||
|
|
@ -41,12 +40,9 @@ PaddleOCR 提供了一份用于训练 icdar2015 数据集的标签文件,通
|
|||
wget -P ./train_data/ic15_data https://paddleocr.bj.bcebos.com/dataset/rec_gt_train.txt
|
||||
# 测试集标签
|
||||
wget -P ./train_data/ic15_data https://paddleocr.bj.bcebos.com/dataset/rec_gt_test.txt
|
||||
|
||||
|
||||
```
|
||||
|
||||
最终训练集应有如下文件结构:
|
||||
|
||||
```
|
||||
|-train_data
|
||||
|-ic15_data
|
||||
|
|
@ -150,7 +146,7 @@ PaddleOCR支持训练和评估交替进行, 可以在 `configs/rec/rec_icdar15_t
|
|||
|
||||
如果验证集很大,测试将会比较耗时,建议减少评估次数,或训练完再进行评估。
|
||||
|
||||
* 提示: 可通过 -c 参数选择 `configs/rec/` 路径下的多种模型配置进行训练,PaddleOCR支持的识别算法有:
|
||||
**提示:** 可通过 -c 参数选择 `configs/rec/` 路径下的多种模型配置进行训练,PaddleOCR支持的识别算法有:
|
||||
|
||||
|
||||
| 配置文件 | 算法名称 | backbone | trans | seq | pred |
|
||||
|
|
|
|||
|
|
@ -28,21 +28,38 @@ deploy/hubserving/ocr_system/
|
|||
# 安装paddlehub
|
||||
pip3 install paddlehub --upgrade -i https://pypi.tuna.tsinghua.edu.cn/simple
|
||||
|
||||
# 设置环境变量
|
||||
# 在Linux下设置环境变量
|
||||
export PYTHONPATH=.
|
||||
# 在Windows下设置环境变量
|
||||
SET PYTHONPATH=.
|
||||
```
|
||||
|
||||
### 2. 安装服务模块
|
||||
PaddleOCR提供3种服务模块,根据需要安装所需模块。如:
|
||||
PaddleOCR提供3种服务模块,根据需要安装所需模块。
|
||||
|
||||
安装检测服务模块:
|
||||
```hub install deploy/hubserving/ocr_det/```
|
||||
* 在Linux环境下,安装示例如下:
|
||||
```shell
|
||||
# 安装检测服务模块:
|
||||
hub install deploy/hubserving/ocr_det/
|
||||
|
||||
或,安装识别服务模块:
|
||||
```hub install deploy/hubserving/ocr_rec/```
|
||||
# 或,安装识别服务模块:
|
||||
hub install deploy/hubserving/ocr_rec/
|
||||
|
||||
或,安装检测+识别串联服务模块:
|
||||
```hub install deploy/hubserving/ocr_system/```
|
||||
# 或,安装检测+识别串联服务模块:
|
||||
hub install deploy/hubserving/ocr_system/
|
||||
```
|
||||
|
||||
* 在Windows环境下(文件夹的分隔符为`\`),安装示例如下:
|
||||
```shell
|
||||
# 安装检测服务模块:
|
||||
hub install deploy\hubserving\ocr_det\
|
||||
|
||||
# 或,安装识别服务模块:
|
||||
hub install deploy\hubserving\ocr_rec\
|
||||
|
||||
# 或,安装检测+识别串联服务模块:
|
||||
hub install deploy\hubserving\ocr_system\
|
||||
```
|
||||
|
||||
### 3. 启动服务
|
||||
#### 方式1. 命令行命令启动(仅支持CPU)
|
||||
|
|
@ -69,7 +86,7 @@ $ hub serving start --modules [Module1==Version1, Module2==Version2, ...] \
|
|||
|
||||
#### 方式2. 配置文件启动(支持CPU、GPU)
|
||||
**启动命令:**
|
||||
```hub serving start --config/-c config.json```
|
||||
```hub serving start -c config.json```
|
||||
|
||||
其中,`config.json`格式如下:
|
||||
```python
|
||||
|
|
@ -157,4 +174,3 @@ hub serving start -c deploy/hubserving/ocr_system/config.json
|
|||
|
||||
- 5、重新启动服务
|
||||
```hub serving start -m ocr_system```
|
||||
|
||||
|
|
|
|||
|
|
@ -1,4 +1,5 @@
|
|||
# 更新
|
||||
- 2020.7.23 发布7月21日B站直播课回放和PPT,PaddleOCR开源大礼包全面解读,[获取地址](https://aistudio.baidu.com/aistudio/course/introduce/1519)
|
||||
- 2020.7.15 添加基于EasyEdge和Paddle-Lite的移动端DEMO,支持iOS和Android系统
|
||||
- 2020.7.15 完善预测部署,添加基于C++预测引擎推理、服务化部署和端侧部署方案,以及超轻量级中文OCR模型预测耗时Benchmark
|
||||
- 2020.7.15 整理OCR相关数据集、常用数据标注以及合成工具
|
||||
|
|
|
|||
|
|
@ -0,0 +1,60 @@
|
|||
# Android Demo quick start
|
||||
|
||||
### 1. Install the latest version of Android Studio
|
||||
|
||||
It can be downloaded from https://developer.android.com/studio . This Demo is written by Android Studio version 4.0.
|
||||
|
||||
### 2. Create a new project
|
||||
|
||||
The NDK version 20b is used in the demo test, and the compilation can be successfully supported for version 20 and above.
|
||||
|
||||
If you are a beginner, you can install and test the NDK compilation environment in the following ways.
|
||||
|
||||
File -> New ->New Project to create "Native C++" project
|
||||
|
||||
1. Start a new Android Studio project
|
||||
|
||||
Select Native C++ in the project template, select Paddle OCR/deploy/android_demo path
|
||||
After entering the project, it will be automatically compiled. The first compilation
|
||||
will take a long time. It is recommended to add an agent to speed up the download.
|
||||
|
||||
**Agent add:**
|
||||
|
||||
Android Studio -> Perferences -> Appearance & Behavior -> System Settings -> HTTP Proxy -> Manual proxy configuration
|
||||
|
||||

|
||||
|
||||
2. Start compilation
|
||||
|
||||
Click the compile button, connect the phone, and follow the instructions of Android Studio to complete the operation.
|
||||
|
||||
When you see the following picture in Android Studio, the compilation is complete:
|
||||
|
||||

|
||||
|
||||
**Tip:** At this time, if the following error message that OpenCV cannot be found appears, please re-click compile,
|
||||
exit the project after compiling, and enter again.
|
||||
|
||||

|
||||
|
||||
### 3. Send to mobile
|
||||
|
||||
Complete the compilation, click Run, and check the effect on the mobile phone.
|
||||
|
||||
### 4. How to customize the demo picture
|
||||
|
||||
1. Image storage path: android_demo/app/src/main/assets/images
|
||||
|
||||
Place the custom picture under this path
|
||||
|
||||
2. Configuration file: android_demo/app/src/main/res/values/strings.xml
|
||||
|
||||
Modify IMAGE_PATH_DEFAULT to a custom picture name
|
||||
|
||||
# Get more support
|
||||
|
||||
Go to [EasyEdge](https://ai.baidu.com/easyedge/app/open_source_demo?referrerUrl=paddlelite) to get more development support:
|
||||
|
||||
- Demo APP: You can use your mobile phone to scan the code to install, which is convenient for the mobile terminal to quickly experience text recognition
|
||||
|
||||
- SDK: The model is packaged to adapt to different chip hardware and operating system SDKs, including a complete interface to facilitate secondary development
|
||||
|
|
@ -60,6 +60,8 @@ Take `rec_icdar15_train.yml` as an example:
|
|||
| beta1 | Set the exponential decay rate for the 1st moment estimates | 0.9 | \ |
|
||||
| beta2 | Set the exponential decay rate for the 2nd moment estimates | 0.999 | \ |
|
||||
| decay | Whether to use decay | \ | \ |
|
||||
| function(decay) | Set the decay function | cosine_decay | Only support cosine_decay |
|
||||
| step_each_epoch | The number of steps in an epoch. | 20 | Calculation :total_image_num / (batch_size_per_card * card_size) |
|
||||
| total_epoch | The number of epochs | 1000 | Consistent with Global.epoch_num |
|
||||
| function(decay) | Set the decay function | cosine_decay | Support cosine_decay and piecewise_decay |
|
||||
| step_each_epoch | The number of steps in an epoch. Used in cosine_decay | 20 | Calculation :total_image_num / (batch_size_per_card * card_size) |
|
||||
| total_epoch | The number of epochs. Used in cosine_decay | 1000 | Consistent with Global.epoch_num |
|
||||
| boundaries | The step intervals to reduce learning rate. Used in piecewise_decay | - | The format is list |
|
||||
| decay_rate | Learning rate decay rate. Used in piecewise_decay | - | \ |
|
||||
|
|
|
|||
|
|
@ -25,7 +25,7 @@ After decompressing the data set and downloading the annotation file, PaddleOCR/
|
|||
The provided annotation file format is as follow, seperated by "\t":
|
||||
```
|
||||
" Image file name Image annotation information encoded by json.dumps"
|
||||
ch4_test_images/img_61.jpg [{"transcription": "MASA", "points": [[310, 104], [416, 141], [418, 216], [312, 179]], ...}]
|
||||
ch4_test_images/img_61.jpg [{"transcription": "MASA", "points": [[310, 104], [416, 141], [418, 216], [312, 179]]}, {...}]
|
||||
```
|
||||
The image annotation after json.dumps() encoding is a list containing multiple dictionaries. The `points` in the dictionary represent the coordinates (x, y) of the four points of the text box, arranged clockwise from the point at the upper left corner.
|
||||
|
||||
|
|
|
|||
|
|
@ -4,28 +4,28 @@ After testing, paddleocr can run on glibc 2.23. You can also test other glibc ve
|
|||
|
||||
PaddleOCR working environment:
|
||||
- PaddlePaddle1.7
|
||||
- python3
|
||||
- python3.7
|
||||
- glibc 2.23
|
||||
|
||||
It is recommended to use the docker provided by us to run PaddleOCR, please refer to the use of docker [link](https://docs.docker.com/get-started/).
|
||||
|
||||
*If you want to directly run the prediction code on mac or windows, you can start from step 2.*
|
||||
|
||||
1. (Recommended) Prepare a docker environment. The first time you use this image, it will be downloaded automatically. Please be patient.
|
||||
**1. (Recommended) Prepare a docker environment. The first time you use this image, it will be downloaded automatically. Please be patient.**
|
||||
```
|
||||
# Switch to the working directory
|
||||
cd /home/Projects
|
||||
# You need to create a docker container for the first run, and do not need to run the current command when you run it again
|
||||
# Create a docker container named ppocr and map the current directory to the /paddle directory of the container
|
||||
|
||||
#If you want to use docker in a CPU environment, use docker instead of nvidia-docker to create docker
|
||||
#If using CPU, use docker instead of nvidia-docker to create docker
|
||||
sudo docker run --name ppocr -v $PWD:/paddle --network=host -it hub.baidubce.com/paddlepaddle/paddle:latest-gpu-cuda9.0-cudnn7-dev /bin/bash
|
||||
```
|
||||
If you have cuda9 installed on your machine, please run the following command to create a container:
|
||||
If using CUDA9, please run the following command to create a container:
|
||||
```
|
||||
sudo nvidia-docker run --name ppocr -v $PWD:/paddle --network=host -it hub.baidubce.com/paddlepaddle/paddle:latest-gpu-cuda9.0-cudnn7-dev /bin/bash
|
||||
```
|
||||
If you have cuda10 installed on your machine, please run the following command to create a container:
|
||||
If using CUDA10, please run the following command to create a container:
|
||||
```
|
||||
sudo nvidia-docker run --name ppocr -v $PWD:/paddle --network=host -it hub.baidubce.com/paddlepaddle/paddle:latest-gpu-cuda10.0-cudnn7-dev /bin/bash
|
||||
```
|
||||
|
|
@ -49,7 +49,7 @@ docker images
|
|||
hub.baidubce.com/paddlepaddle/paddle latest-gpu-cuda9.0-cudnn7-dev f56310dcc829
|
||||
```
|
||||
|
||||
2. Install PaddlePaddle Fluid v1.7 (the higher version is not supported yet, the adaptation work is in progress)
|
||||
**2. Install PaddlePaddle Fluid v1.7 (the higher version is not supported yet, the adaptation work is in progress)**
|
||||
```
|
||||
pip3 install --upgrade pip
|
||||
|
||||
|
|
@ -65,7 +65,7 @@ python3 -m pip install paddlepaddle==1.7.2 -i https://pypi.tuna.tsinghua.edu.cn/
|
|||
For more software version requirements, please refer to the instructions in [Installation Document](https://www.paddlepaddle.org.cn/install/quick) for operation.
|
||||
|
||||
|
||||
3. Clone PaddleOCR repo
|
||||
**3. Clone PaddleOCR repo**
|
||||
```
|
||||
# Recommend
|
||||
git clone https://github.com/PaddlePaddle/PaddleOCR
|
||||
|
|
@ -77,8 +77,14 @@ git clone https://gitee.com/paddlepaddle/PaddleOCR
|
|||
# Note: The cloud-hosting code may not be able to synchronize the update with this GitHub project in real time. There might be a delay of 3-5 days. Please give priority to the recommended method.
|
||||
```
|
||||
|
||||
4. Install third-party libraries
|
||||
**4. Install third-party libraries**
|
||||
```
|
||||
cd PaddleOCR
|
||||
pip3 install -r requirments.txt
|
||||
```
|
||||
|
||||
If you getting this error `OSError: [WinError 126] The specified module could not be found` when you install shapely on windows.
|
||||
|
||||
Please try to download Shapely whl file using [http://www.lfd.uci.edu/~gohlke/pythonlibs/#shapely](http://www.lfd.uci.edu/~gohlke/pythonlibs/#shapely).
|
||||
|
||||
Reference: [Solve shapely installation on windows](https://stackoverflow.com/questions/44398265/install-shapely-oserror-winerror-126-the-specified-module-could-not-be-found)
|
||||
|
|
|
|||
|
|
@ -29,26 +29,39 @@ The following steps take the 2-stage series service as an example. If only the d
|
|||
# Install paddlehub
|
||||
pip3 install paddlehub --upgrade -i https://pypi.tuna.tsinghua.edu.cn/simple
|
||||
|
||||
# Set environment variables
|
||||
# Set environment variables on Linux
|
||||
export PYTHONPATH=.
|
||||
# Set environment variables on Windows
|
||||
SET PYTHONPATH=.
|
||||
```
|
||||
|
||||
### 2. Install Service Module
|
||||
PaddleOCR provides 3 kinds of service modules, install the required modules according to your needs. Such as:
|
||||
PaddleOCR provides 3 kinds of service modules, install the required modules according to your needs.
|
||||
|
||||
Install the detection service module:
|
||||
* On Linux platform, the examples are as follows.
|
||||
```shell
|
||||
# Install the detection service module:
|
||||
hub install deploy/hubserving/ocr_det/
|
||||
```
|
||||
Or, install the recognition service module:
|
||||
```shell
|
||||
|
||||
# Or, install the recognition service module:
|
||||
hub install deploy/hubserving/ocr_rec/
|
||||
```
|
||||
Or, install the 2-stage series service module:
|
||||
```shell
|
||||
|
||||
# Or, install the 2-stage series service module:
|
||||
hub install deploy/hubserving/ocr_system/
|
||||
```
|
||||
|
||||
* On Windows platform, the examples are as follows.
|
||||
```shell
|
||||
# Install the detection service module:
|
||||
hub install deploy\hubserving\ocr_det\
|
||||
|
||||
# Or, install the recognition service module:
|
||||
hub install deploy\hubserving\ocr_rec\
|
||||
|
||||
# Or, install the 2-stage series service module:
|
||||
hub install deploy\hubserving\ocr_system\
|
||||
```
|
||||
|
||||
### 3. Start service
|
||||
#### Way 1. Start with command line parameters (CPU only)
|
||||
|
||||
|
|
|
|||
|
|
@ -1,5 +1,5 @@
|
|||
# RECENT UPDATES
|
||||
|
||||
- 2020.7.23, Release the playback and PPT of live class on BiliBili station, PaddleOCR Introduction, [address](https://aistudio.baidu.com/aistudio/course/introduce/1519)
|
||||
- 2020.7.15, Add mobile App demo , support both iOS and Android ( based on easyedge and Paddle Lite)
|
||||
- 2020.7.15, Improve the deployment ability, add the C + + inference , serving deployment. In addtion, the benchmarks of the ultra-lightweight Chinese OCR model are provided.
|
||||
- 2020.7.15, Add several related datasets, data annotation and synthesis tools.
|
||||
|
|
|
|||
|
|
@ -17,7 +17,7 @@ import cv2
|
|||
import numpy as np
|
||||
import json
|
||||
import sys
|
||||
from ppocr.utils.utility import initial_logger
|
||||
from ppocr.utils.utility import initial_logger, check_and_read_gif
|
||||
logger = initial_logger()
|
||||
|
||||
from .data_augment import AugmentData
|
||||
|
|
@ -100,6 +100,8 @@ class DBProcessTrain(object):
|
|||
|
||||
def __call__(self, label_infor):
|
||||
img_path, gt_label = self.convert_label_infor(label_infor)
|
||||
imgvalue, flag = check_and_read_gif(img_path)
|
||||
if not flag:
|
||||
imgvalue = cv2.imread(img_path)
|
||||
if imgvalue is None:
|
||||
logger.info("{} does not exist!".format(img_path))
|
||||
|
|
|
|||
|
|
@ -17,6 +17,7 @@ import cv2
|
|||
import numpy as np
|
||||
import json
|
||||
import sys
|
||||
import os
|
||||
|
||||
class EASTProcessTrain(object):
|
||||
def __init__(self, params):
|
||||
|
|
@ -52,7 +53,7 @@ class EASTProcessTrain(object):
|
|||
label_infor = label_infor.decode()
|
||||
label_infor = label_infor.encode('utf-8').decode('utf-8-sig')
|
||||
substr = label_infor.strip("\n").split("\t")
|
||||
img_path = self.img_set_dir + substr[0]
|
||||
img_path = os.path.join(self.img_set_dir, substr[0])
|
||||
label = json.loads(substr[1])
|
||||
nBox = len(label)
|
||||
wordBBs, txts, txt_tags = [], [], []
|
||||
|
|
|
|||
|
|
@ -185,6 +185,7 @@ class SimpleReader(object):
|
|||
if params['mode'] != 'test':
|
||||
self.img_set_dir = params['img_set_dir']
|
||||
self.label_file_path = params['label_file_path']
|
||||
self.use_gpu = params['use_gpu']
|
||||
self.char_ops = params['char_ops']
|
||||
self.image_shape = params['image_shape']
|
||||
self.loss_type = params['loss_type']
|
||||
|
|
@ -213,6 +214,15 @@ class SimpleReader(object):
|
|||
if self.mode != 'train':
|
||||
process_id = 0
|
||||
|
||||
def get_device_num():
|
||||
if self.use_gpu:
|
||||
gpus = os.environ.get("CUDA_VISIBLE_DEVICES", 1)
|
||||
gpu_num = len(gpus.split(','))
|
||||
return gpu_num
|
||||
else:
|
||||
cpu_num = os.environ.get("CPU_NUM", 1)
|
||||
return int(cpu_num)
|
||||
|
||||
def sample_iter_reader():
|
||||
if self.mode != 'train' and self.infer_img is not None:
|
||||
image_file_list = get_image_file_list(self.infer_img)
|
||||
|
|
@ -233,10 +243,16 @@ class SimpleReader(object):
|
|||
img_num = len(label_infor_list)
|
||||
img_id_list = list(range(img_num))
|
||||
random.shuffle(img_id_list)
|
||||
if sys.platform == "win32":
|
||||
if sys.platform == "win32" and self.num_workers != 1:
|
||||
print("multiprocess is not fully compatible with Windows."
|
||||
"num_workers will be 1.")
|
||||
self.num_workers = 1
|
||||
if self.batch_size * get_device_num(
|
||||
) * self.num_workers > img_num:
|
||||
raise Exception(
|
||||
"The number of the whole data ({}) is smaller than the batch_size * devices_num * num_workers ({})".
|
||||
format(img_num, self.batch_size * get_device_num() *
|
||||
self.num_workers))
|
||||
for img_id in range(process_id, img_num, self.num_workers):
|
||||
label_infor = label_infor_list[img_id_list[img_id]]
|
||||
substr = label_infor.decode('utf-8').strip("\n").split("\t")
|
||||
|
|
|
|||
|
|
@ -360,7 +360,7 @@ def process_image(img,
|
|||
text = char_ops.encode(label)
|
||||
if len(text) == 0 or len(text) > max_text_length:
|
||||
logger.info(
|
||||
"Warning in ppocr/data/rec/img_tools.py:line362: Wrong data type."
|
||||
"Warning in ppocr/data/rec/img_tools.py: Wrong data type."
|
||||
"Excepted string with length between 1 and {}, but "
|
||||
"got '{}'. Label is '{}'".format(max_text_length,
|
||||
len(text), label))
|
||||
|
|
|
|||
|
|
@ -31,16 +31,28 @@ __all__ = [
|
|||
|
||||
class MobileNetV3():
|
||||
def __init__(self, params):
|
||||
self.scale = params['scale']
|
||||
model_name = params['model_name']
|
||||
self.scale = params.get("scale", 0.5)
|
||||
model_name = params.get("model_name", "small")
|
||||
large_stride = params.get("large_stride", [1, 2, 2, 2])
|
||||
small_stride = params.get("small_stride", [2, 2, 2, 2])
|
||||
|
||||
assert isinstance(large_stride, list), "large_stride type must " \
|
||||
"be list but got {}".format(type(large_stride))
|
||||
assert isinstance(small_stride, list), "small_stride type must " \
|
||||
"be list but got {}".format(type(small_stride))
|
||||
assert len(large_stride) == 4, "large_stride length must be " \
|
||||
"4 but got {}".format(len(large_stride))
|
||||
assert len(small_stride) == 4, "small_stride length must be " \
|
||||
"4 but got {}".format(len(small_stride))
|
||||
|
||||
self.inplanes = 16
|
||||
if model_name == "large":
|
||||
self.cfg = [
|
||||
# k, exp, c, se, nl, s,
|
||||
[3, 16, 16, False, 'relu', 1],
|
||||
[3, 64, 24, False, 'relu', (2, 1)],
|
||||
[3, 16, 16, False, 'relu', large_stride[0]],
|
||||
[3, 64, 24, False, 'relu', (large_stride[1], 1)],
|
||||
[3, 72, 24, False, 'relu', 1],
|
||||
[5, 72, 40, True, 'relu', (2, 1)],
|
||||
[5, 72, 40, True, 'relu', (large_stride[2], 1)],
|
||||
[5, 120, 40, True, 'relu', 1],
|
||||
[5, 120, 40, True, 'relu', 1],
|
||||
[3, 240, 80, False, 'hard_swish', 1],
|
||||
|
|
@ -49,7 +61,7 @@ class MobileNetV3():
|
|||
[3, 184, 80, False, 'hard_swish', 1],
|
||||
[3, 480, 112, True, 'hard_swish', 1],
|
||||
[3, 672, 112, True, 'hard_swish', 1],
|
||||
[5, 672, 160, True, 'hard_swish', (2, 1)],
|
||||
[5, 672, 160, True, 'hard_swish', (large_stride[3], 1)],
|
||||
[5, 960, 160, True, 'hard_swish', 1],
|
||||
[5, 960, 160, True, 'hard_swish', 1],
|
||||
]
|
||||
|
|
@ -58,15 +70,15 @@ class MobileNetV3():
|
|||
elif model_name == "small":
|
||||
self.cfg = [
|
||||
# k, exp, c, se, nl, s,
|
||||
[3, 16, 16, True, 'relu', (2, 1)],
|
||||
[3, 72, 24, False, 'relu', (2, 1)],
|
||||
[3, 16, 16, True, 'relu', (small_stride[0], 1)],
|
||||
[3, 72, 24, False, 'relu', (small_stride[1], 1)],
|
||||
[3, 88, 24, False, 'relu', 1],
|
||||
[5, 96, 40, True, 'hard_swish', (2, 1)],
|
||||
[5, 96, 40, True, 'hard_swish', (small_stride[2], 1)],
|
||||
[5, 240, 40, True, 'hard_swish', 1],
|
||||
[5, 240, 40, True, 'hard_swish', 1],
|
||||
[5, 120, 48, True, 'hard_swish', 1],
|
||||
[5, 144, 48, True, 'hard_swish', 1],
|
||||
[5, 288, 96, True, 'hard_swish', (2, 1)],
|
||||
[5, 288, 96, True, 'hard_swish', (small_stride[3], 1)],
|
||||
[5, 576, 96, True, 'hard_swish', 1],
|
||||
[5, 576, 96, True, 'hard_swish', 1],
|
||||
]
|
||||
|
|
@ -78,7 +90,7 @@ class MobileNetV3():
|
|||
|
||||
supported_scale = [0.35, 0.5, 0.75, 1.0, 1.25]
|
||||
assert self.scale in supported_scale, \
|
||||
"supported scale are {} but input scale is {}".format(supported_scale, scale)
|
||||
"supported scales are {} but input scale is {}".format(supported_scale, self.scale)
|
||||
|
||||
def __call__(self, input):
|
||||
scale = self.scale
|
||||
|
|
|
|||
|
|
@ -32,6 +32,7 @@ class CTCPredict(object):
|
|||
self.char_num = params['char_num']
|
||||
self.encoder = SequenceEncoder(params)
|
||||
self.encoder_type = params['encoder_type']
|
||||
self.fc_decay = params.get("fc_decay", 0.0004)
|
||||
|
||||
def __call__(self, inputs, labels=None, mode=None):
|
||||
encoder_features = self.encoder(inputs)
|
||||
|
|
@ -39,7 +40,7 @@ class CTCPredict(object):
|
|||
encoder_features = fluid.layers.concat(encoder_features, axis=1)
|
||||
name = "ctc_fc"
|
||||
para_attr, bias_attr = get_para_bias_attr(
|
||||
l2_decay=0.0004, k=encoder_features.shape[1], name=name)
|
||||
l2_decay=self.fc_decay, k=encoder_features.shape[1], name=name)
|
||||
predict = fluid.layers.fc(input=encoder_features,
|
||||
size=self.char_num + 1,
|
||||
param_attr=para_attr,
|
||||
|
|
|
|||
|
|
@ -14,6 +14,9 @@
|
|||
|
||||
import logging
|
||||
import os
|
||||
import imghdr
|
||||
import cv2
|
||||
from paddle import fluid
|
||||
|
||||
|
||||
def initial_logger():
|
||||
|
|
@ -61,19 +64,31 @@ def get_image_file_list(img_file):
|
|||
if img_file is None or not os.path.exists(img_file):
|
||||
raise Exception("not found any img file in {}".format(img_file))
|
||||
|
||||
img_end = ['jpg', 'png', 'jpeg', 'JPEG', 'JPG', 'bmp']
|
||||
if os.path.isfile(img_file) and img_file.split('.')[-1] in img_end:
|
||||
img_end = {'jpg', 'bmp', 'png', 'jpeg', 'rgb', 'tif', 'tiff', 'gif', 'GIF'}
|
||||
if os.path.isfile(img_file) and imghdr.what(img_file) in img_end:
|
||||
imgs_lists.append(img_file)
|
||||
elif os.path.isdir(img_file):
|
||||
for single_file in os.listdir(img_file):
|
||||
if single_file.split('.')[-1] in img_end:
|
||||
imgs_lists.append(os.path.join(img_file, single_file))
|
||||
file_path = os.path.join(img_file, single_file)
|
||||
if imghdr.what(file_path) in img_end:
|
||||
imgs_lists.append(file_path)
|
||||
if len(imgs_lists) == 0:
|
||||
raise Exception("not found any img file in {}".format(img_file))
|
||||
return imgs_lists
|
||||
|
||||
|
||||
from paddle import fluid
|
||||
def check_and_read_gif(img_path):
|
||||
if os.path.basename(img_path)[-3:] in ['gif', 'GIF']:
|
||||
gif = cv2.VideoCapture(img_path)
|
||||
ret, frame = gif.read()
|
||||
if not ret:
|
||||
logging.info("Cannot read {}. This gif image maybe corrupted.")
|
||||
return None, False
|
||||
if len(frame.shape) == 2 or frame.shape[-1] == 1:
|
||||
frame = cv2.cvtColor(frame, cv2.COLOR_GRAY2RGB)
|
||||
imgvalue = frame[:, :, ::-1]
|
||||
return imgvalue, True
|
||||
return None, False
|
||||
|
||||
|
||||
def create_multi_devices_program(program, loss_var_name):
|
||||
|
|
|
|||
|
|
@ -41,27 +41,11 @@ from paddle import fluid
|
|||
from ppocr.utils.utility import initial_logger
|
||||
logger = initial_logger()
|
||||
from ppocr.utils.save_load import init_model
|
||||
from ppocr.utils.character import CharacterOps
|
||||
from ppocr.utils.utility import create_module
|
||||
|
||||
|
||||
|
||||
def main():
|
||||
config = program.load_config(FLAGS.config)
|
||||
program.merge_config(FLAGS.opt)
|
||||
logger.info(config)
|
||||
|
||||
# check if set use_gpu=True in paddlepaddle cpu version
|
||||
use_gpu = config['Global']['use_gpu']
|
||||
program.check_gpu(use_gpu)
|
||||
|
||||
alg = config['Global']['algorithm']
|
||||
assert alg in ['EAST', 'DB', 'Rosetta', 'CRNN', 'STARNet', 'RARE']
|
||||
if alg in ['Rosetta', 'CRNN', 'STARNet', 'RARE']:
|
||||
config['Global']['char_ops'] = CharacterOps(config['Global'])
|
||||
|
||||
place = fluid.CUDAPlace(0) if use_gpu else fluid.CPUPlace()
|
||||
startup_prog = fluid.Program()
|
||||
eval_program = fluid.Program()
|
||||
startup_prog, eval_program, place, config, _ = program.preprocess()
|
||||
|
||||
feeded_var_names, target_vars, fetches_var_name = program.build_export(
|
||||
config, eval_program, startup_prog)
|
||||
|
|
@ -88,6 +72,4 @@ def main():
|
|||
|
||||
|
||||
if __name__ == '__main__':
|
||||
parser = program.ArgsParser()
|
||||
FLAGS = parser.parse_args()
|
||||
main()
|
||||
|
|
|
|||
|
|
@ -20,7 +20,7 @@ sys.path.append(os.path.join(__dir__, '../..'))
|
|||
import tools.infer.utility as utility
|
||||
from ppocr.utils.utility import initial_logger
|
||||
logger = initial_logger()
|
||||
from ppocr.utils.utility import get_image_file_list
|
||||
from ppocr.utils.utility import get_image_file_list, check_and_read_gif
|
||||
import cv2
|
||||
from ppocr.data.det.east_process import EASTProcessTest
|
||||
from ppocr.data.det.db_process import DBProcessTest
|
||||
|
|
@ -135,7 +135,12 @@ if __name__ == "__main__":
|
|||
text_detector = TextDetector(args)
|
||||
count = 0
|
||||
total_time = 0
|
||||
draw_img_save = "./inference_results"
|
||||
if not os.path.exists(draw_img_save):
|
||||
os.makedirs(draw_img_save)
|
||||
for image_file in image_file_list:
|
||||
img, flag = check_and_read_gif(image_file)
|
||||
if not flag:
|
||||
img = cv2.imread(image_file)
|
||||
if img is None:
|
||||
logger.info("error in loading image:{}".format(image_file))
|
||||
|
|
@ -147,6 +152,7 @@ if __name__ == "__main__":
|
|||
print("Predict time of %s:" % image_file, elapse)
|
||||
src_im = utility.draw_text_det_res(dt_boxes, image_file)
|
||||
img_name_pure = image_file.split("/")[-1]
|
||||
cv2.imwrite("./inference_results/det_res_%s" % img_name_pure, src_im)
|
||||
cv2.imwrite(
|
||||
os.path.join(draw_img_save, "det_res_%s" % img_name_pure), src_im)
|
||||
if count > 1:
|
||||
print("Avg Time:", total_time / (count - 1))
|
||||
|
|
|
|||
|
|
@ -20,7 +20,7 @@ sys.path.append(os.path.abspath(os.path.join(__dir__, '../..')))
|
|||
import tools.infer.utility as utility
|
||||
from ppocr.utils.utility import initial_logger
|
||||
logger = initial_logger()
|
||||
from ppocr.utils.utility import get_image_file_list
|
||||
from ppocr.utils.utility import get_image_file_list, check_and_read_gif
|
||||
import cv2
|
||||
import copy
|
||||
import numpy as np
|
||||
|
|
@ -122,9 +122,9 @@ class TextRecognizer(object):
|
|||
ind = np.argmax(probs, axis=1)
|
||||
blank = probs.shape[1]
|
||||
valid_ind = np.where(ind != (blank - 1))[0]
|
||||
score = np.mean(probs[valid_ind, ind[valid_ind]])
|
||||
if len(valid_ind) == 0:
|
||||
continue
|
||||
score = np.mean(probs[valid_ind, ind[valid_ind]])
|
||||
# rec_res.append([preds_text, score])
|
||||
rec_res[indices[beg_img_no + rno]] = [preds_text, score]
|
||||
else:
|
||||
|
|
@ -153,7 +153,9 @@ def main(args):
|
|||
valid_image_file_list = []
|
||||
img_list = []
|
||||
for image_file in image_file_list:
|
||||
img = cv2.imread(image_file, cv2.IMREAD_COLOR)
|
||||
img, flag = check_and_read_gif(image_file)
|
||||
if not flag:
|
||||
img = cv2.imread(image_file)
|
||||
if img is None:
|
||||
logger.info("error in loading image:{}".format(image_file))
|
||||
continue
|
||||
|
|
|
|||
|
|
@ -27,7 +27,7 @@ import copy
|
|||
import numpy as np
|
||||
import math
|
||||
import time
|
||||
from ppocr.utils.utility import get_image_file_list
|
||||
from ppocr.utils.utility import get_image_file_list, check_and_read_gif
|
||||
from PIL import Image
|
||||
from tools.infer.utility import draw_ocr
|
||||
from tools.infer.utility import draw_ocr_box_txt
|
||||
|
|
@ -49,16 +49,21 @@ class TextSystem(object):
|
|||
points[:, 0] = points[:, 0] - left
|
||||
points[:, 1] = points[:, 1] - top
|
||||
'''
|
||||
img_crop_width = int(max(np.linalg.norm(points[0] - points[1]),
|
||||
img_crop_width = int(
|
||||
max(
|
||||
np.linalg.norm(points[0] - points[1]),
|
||||
np.linalg.norm(points[2] - points[3])))
|
||||
img_crop_height = int(max(np.linalg.norm(points[0] - points[3]),
|
||||
img_crop_height = int(
|
||||
max(
|
||||
np.linalg.norm(points[0] - points[3]),
|
||||
np.linalg.norm(points[1] - points[2])))
|
||||
pts_std = np.float32([[0, 0],
|
||||
[img_crop_width, 0],
|
||||
pts_std = np.float32([[0, 0], [img_crop_width, 0],
|
||||
[img_crop_width, img_crop_height],
|
||||
[0, img_crop_height]])
|
||||
M = cv2.getPerspectiveTransform(points, pts_std)
|
||||
dst_img = cv2.warpPerspective(img, M, (img_crop_width, img_crop_height),
|
||||
dst_img = cv2.warpPerspective(
|
||||
img,
|
||||
M, (img_crop_width, img_crop_height),
|
||||
borderMode=cv2.BORDER_REPLICATE,
|
||||
flags=cv2.INTER_CUBIC)
|
||||
dst_img_height, dst_img_width = dst_img.shape[0:2]
|
||||
|
|
@ -119,6 +124,8 @@ def main(args):
|
|||
is_visualize = True
|
||||
tackle_img_num = 0
|
||||
for image_file in image_file_list:
|
||||
img, flag = check_and_read_gif(image_file)
|
||||
if not flag:
|
||||
img = cv2.imread(image_file)
|
||||
if img is None:
|
||||
logger.info("error in loading image:{}".format(image_file))
|
||||
|
|
@ -130,14 +137,14 @@ def main(args):
|
|||
dt_boxes, rec_res = text_sys(img)
|
||||
elapse = time.time() - starttime
|
||||
print("Predict time of %s: %.3fs" % (image_file, elapse))
|
||||
|
||||
drop_score = 0.5
|
||||
dt_num = len(dt_boxes)
|
||||
dt_boxes_final = []
|
||||
for dno in range(dt_num):
|
||||
text, score = rec_res[dno]
|
||||
if score >= 0.5:
|
||||
if score >= drop_score:
|
||||
text_str = "%s, %.3f" % (text, score)
|
||||
print(text_str)
|
||||
dt_boxes_final.append(dt_boxes[dno])
|
||||
|
||||
if is_visualize:
|
||||
image = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
|
||||
|
|
@ -146,7 +153,12 @@ def main(args):
|
|||
scores = [rec_res[i][1] for i in range(len(rec_res))]
|
||||
|
||||
draw_img = draw_ocr(
|
||||
image, boxes, txts, scores, draw_txt=True, drop_score=0.5)
|
||||
image,
|
||||
boxes,
|
||||
txts,
|
||||
scores,
|
||||
draw_txt=True,
|
||||
drop_score=drop_score)
|
||||
draw_img_save = "./inference_results/"
|
||||
if not os.path.exists(draw_img_save):
|
||||
os.makedirs(draw_img_save)
|
||||
|
|
|
|||
|
|
@ -169,7 +169,7 @@ def draw_ocr_box_txt(image, boxes, txts):
|
|||
img_right = Image.new('RGB', (w, h), (255, 255, 255))
|
||||
|
||||
import random
|
||||
# 每次使用相同的随机种子 ,可以保证两次颜色一致
|
||||
|
||||
random.seed(0)
|
||||
draw_left = ImageDraw.Draw(img_left)
|
||||
draw_right = ImageDraw.Draw(img_right)
|
||||
|
|
|
|||
|
|
@ -42,27 +42,10 @@ from ppocr.utils.utility import initial_logger
|
|||
logger = initial_logger()
|
||||
from ppocr.data.reader_main import reader_main
|
||||
from ppocr.utils.save_load import init_model
|
||||
from ppocr.utils.character import CharacterOps
|
||||
from paddle.fluid.contrib.model_stat import summary
|
||||
|
||||
|
||||
def main():
|
||||
config = program.load_config(FLAGS.config)
|
||||
program.merge_config(FLAGS.opt)
|
||||
logger.info(config)
|
||||
|
||||
# check if set use_gpu=True in paddlepaddle cpu version
|
||||
use_gpu = config['Global']['use_gpu']
|
||||
program.check_gpu(use_gpu)
|
||||
|
||||
alg = config['Global']['algorithm']
|
||||
assert alg in ['EAST', 'DB', 'Rosetta', 'CRNN', 'STARNet', 'RARE']
|
||||
if alg in ['Rosetta', 'CRNN', 'STARNet', 'RARE']:
|
||||
config['Global']['char_ops'] = CharacterOps(config['Global'])
|
||||
|
||||
place = fluid.CUDAPlace(0) if use_gpu else fluid.CPUPlace()
|
||||
startup_program = fluid.Program()
|
||||
train_program = fluid.Program()
|
||||
train_build_outputs = program.build(
|
||||
config, train_program, startup_program, mode='train')
|
||||
train_loader = train_build_outputs[0]
|
||||
|
|
@ -91,7 +74,7 @@ def main():
|
|||
|
||||
# dump mode structure
|
||||
if config['Global']['debug']:
|
||||
if 'attention' in config['Global']['loss_type']:
|
||||
if train_alg_type == 'rec' and 'attention' in config['Global']['loss_type']:
|
||||
logger.warning('Does not suport dump attention...')
|
||||
else:
|
||||
summary(train_program)
|
||||
|
|
@ -109,15 +92,13 @@ def main():
|
|||
'fetch_name_list':eval_fetch_name_list,\
|
||||
'fetch_varname_list':eval_fetch_varname_list}
|
||||
|
||||
if alg in ['EAST', 'DB']:
|
||||
if train_alg_type == 'det':
|
||||
program.train_eval_det_run(config, exe, train_info_dict, eval_info_dict)
|
||||
else:
|
||||
program.train_eval_rec_run(config, exe, train_info_dict, eval_info_dict)
|
||||
|
||||
|
||||
def test_reader():
|
||||
config = program.load_config(FLAGS.config)
|
||||
program.merge_config(FLAGS.opt)
|
||||
logger.info(config)
|
||||
train_reader = reader_main(config=config, mode="train")
|
||||
import time
|
||||
|
|
@ -136,7 +117,6 @@ def test_reader():
|
|||
|
||||
|
||||
if __name__ == '__main__':
|
||||
parser = program.ArgsParser()
|
||||
FLAGS = parser.parse_args()
|
||||
startup_program, train_program, place, config, train_alg_type = program.preprocess()
|
||||
main()
|
||||
# test_reader()
|
||||
|
|
|
|||
Loading…
Reference in New Issue