2.8 KiB
2.8 KiB
PaddleStructure
安装layoutparser
pip3 install https://paddleocr.bj.bcebos.com/whl/layoutparser-0.0.0-py3-none-any.whl
1. pipeline介绍
PaddleStructure 是一个用于复杂板式文字OCR的工具包,流程如下
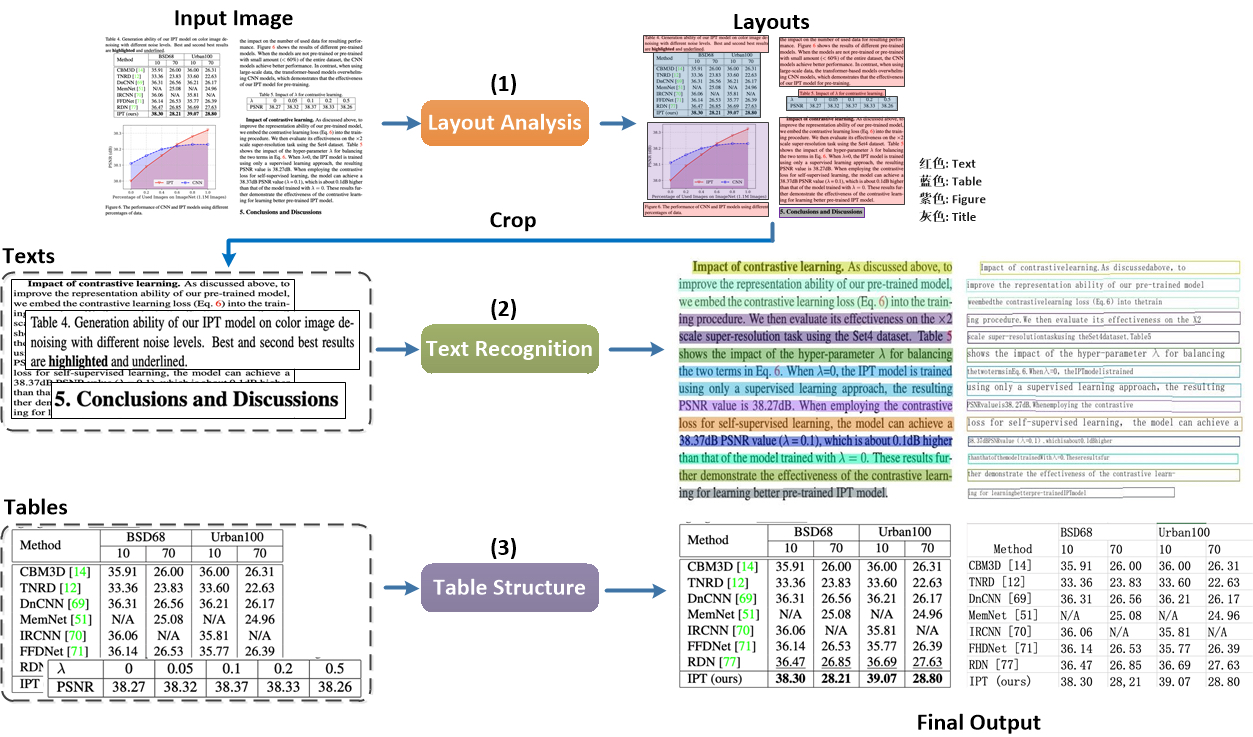
在PaddleStructure中,图片会先经由layoutparser进行版面分析,在版面分析中,会对图片里的区域进行分类,根据根据类别进行对于的ocr流程。
目前layoutparser会输出五个类别:
- Text
- Title
- Figure
- List
- Table
1-4类走传统的OCR流程,5走表格的OCR流程。
2. LayoutParser
3. Table OCR
4. 预测引擎推理
使用如下命令即可完成预测引擎的推理
python3 predict_system.py --det_model_dir=path/to/det_model_dir --rec_model_dir=path/to/rec_model_dir --table_model_dir=path/to/table_model_dir --image_dir=../doc/table/1.png --rec_char_dict_path=../ppocr/utils/dict/table_dict.txt --table_char_dict_path=../ppocr/utils/dict/table_structure_dict.txt --rec_char_type=EN --det_limit_side_len=736 --det_limit_type=min --output ../output/table
运行完成后,每张图片会output字段指定的目录下有一个同名目录,图片里的每个表格会存储为一个excel,excel文件名为表格在图片里的坐标。
5. PaddleStructure whl包介绍
5.1 使用
5.1.1 代码使用
import os
import cv2
from paddlestructure import PaddleStructure,draw_result,save_res
table_engine = PaddleStructure(show_log=True)
save_folder = './output/table'
img_path = '../doc/table/1.png'
img = cv2.imread(img_path)
result = table_engine(img)
save_res(result, save_folder,os.path.basename(img_path).split('.')[0])
for line in result:
print(line)
from PIL import Image
font_path = 'path/to/PaddleOCR/doc/fonts/simfang.ttf'
image = Image.open(img_path).convert('RGB')
im_show = draw_result(image, result,font_path=font_path)
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')
5.1.2 命令行使用
paddlestructure --image_dir=../doc/table/1.png
参数说明
大部分参数和paddleocr whl包保持一致,见 whl包文档
| 字段 | 说明 | 默认值 |
|---|---|---|
| output | excel和识别结果保存的地址 | ./output/table |
| table_max_len | 表格结构模型预测时,图像的长边resize尺度 | 488 |
| table_model_dir | 表格结构模型 inference 模型地址 | None |
| table_char_type | 表格结构模型所用字典地址 | ../ppocr/utils/dict/table_structure_dict.tx |