|
|
||
|---|---|---|
| configs | ||
| deploy | ||
| doc | ||
| ppocr | ||
| tools | ||
| train_data | ||
| .clang_format.hook | ||
| .gitignore | ||
| .pre-commit-config.yaml | ||
| .style.yapf | ||
| LICENSE | ||
| MANIFEST.in | ||
| README.md | ||
| README_ch.md | ||
| __init__.py | ||
| paddleocr.py | ||
| requirments.txt | ||
| setup.py | ||
README.md
English | 简体中文
Introduction
PaddleOCR aims to create rich, leading, and practical OCR tools that help users train better models and apply them into practice.
Recent updates
- 2020.9.22 Update the PP-OCR technical article, https://arxiv.org/abs/2009.09941
- 2020.9.19 Update the ultra lightweight compressed ppocr_mobile_slim series models, the overall model size is 3.5M (see PP-OCR Pipeline), suitable for mobile deployment. Model Downloads
- 2020.9.17 Update the ultra lightweight ppocr_mobile series and general ppocr_server series Chinese and English ocr models, which are comparable to commercial effects. Model Downloads
- 2020.9.17 update English recognition model and Multilingual recognition model,
German,French,JapaneseandKoreanhave been supported. Models for more languages will continue to be updated. - 2020.8.24 Support the use of PaddleOCR through whl package installation,please refer PaddleOCR Package
- 2020.8.21 Update the replay and PPT of the live lesson at Bilibili on August 18, lesson 2, easy to learn and use OCR tool spree. Get Address
- more
Features
- PPOCR series of high-quality pre-trained models, comparable to commercial effects
- Ultra lightweight ppocr_mobile series models: detection (2.6M) + direction classifier (0.9M) + recognition (4.6M) = 8.1M
- General ppocr_server series models: detection (47.2M) + direction classifier (0.9M) + recognition (107M) = 155.1M
- Ultra lightweight compression ppocr_mobile_slim series models: detection (1.4M) + direction classifier (0.5M) + recognition (1.6M) = 3.5M
- Support Chinese, English, and digit recognition, vertical text recognition, and long text recognition
- Support multi-language recognition: Korean, Japanese, German, French
- Support user-defined training, provides rich predictive inference deployment solutions
- Support PIP installation, easy to use
- Support Linux, Windows, MacOS and other systems
Visualization


The above pictures are the visualizations of the general ppocr_server model. For more effect pictures, please see More visualizations.
Community
- Scan the QR code below with your Wechat, you can access to official technical exchange group. Look forward to your participation.

Quick Experience
You can also quickly experience the ultra-lightweight OCR : Online Experience
Mobile DEMO experience (based on EasyEdge and Paddle-Lite, supports iOS and Android systems): Sign in to the website to obtain the QR code for installing the App
Also, you can scan the QR code below to install the App (Android support only)

PP-OCR 1.1 series model list(Update on Sep 17)
| Model introduction | Model name | Recommended scene | Detection model | Direction classifier | Recognition model |
|---|---|---|---|---|---|
| Chinese and English ultra-lightweight OCR model (8.1M) | ch_ppocr_mobile_v1.1_xx | Mobile & server | inference model / pre-trained model | inference model / pre-trained model | inference model / pre-trained model |
| Chinese and English general OCR model (155.1M) | ch_ppocr_server_v1.1_xx | Server | inference model / pre-trained model | inference model / pre-trained model | inference model / pre-trained model |
| Chinese and English ultra-lightweight compressed OCR model (3.5M) | ch_ppocr_mobile_slim_v1.1_xx | Mobile | inference model / slim model | inference model / slim model | inference model / slim model |
For more model downloads (including multiple languages), please refer to PP-OCR v1.1 series model downloads
Tutorials
- Installation
- Quick Start
- Code Structure
- Algorithm introduction
- Model training/evaluation
- Inference and Deployment
- Datasets
- Visualization
- FAQ
- Community
- References
- License
- Contribution
PP-OCR Pipeline
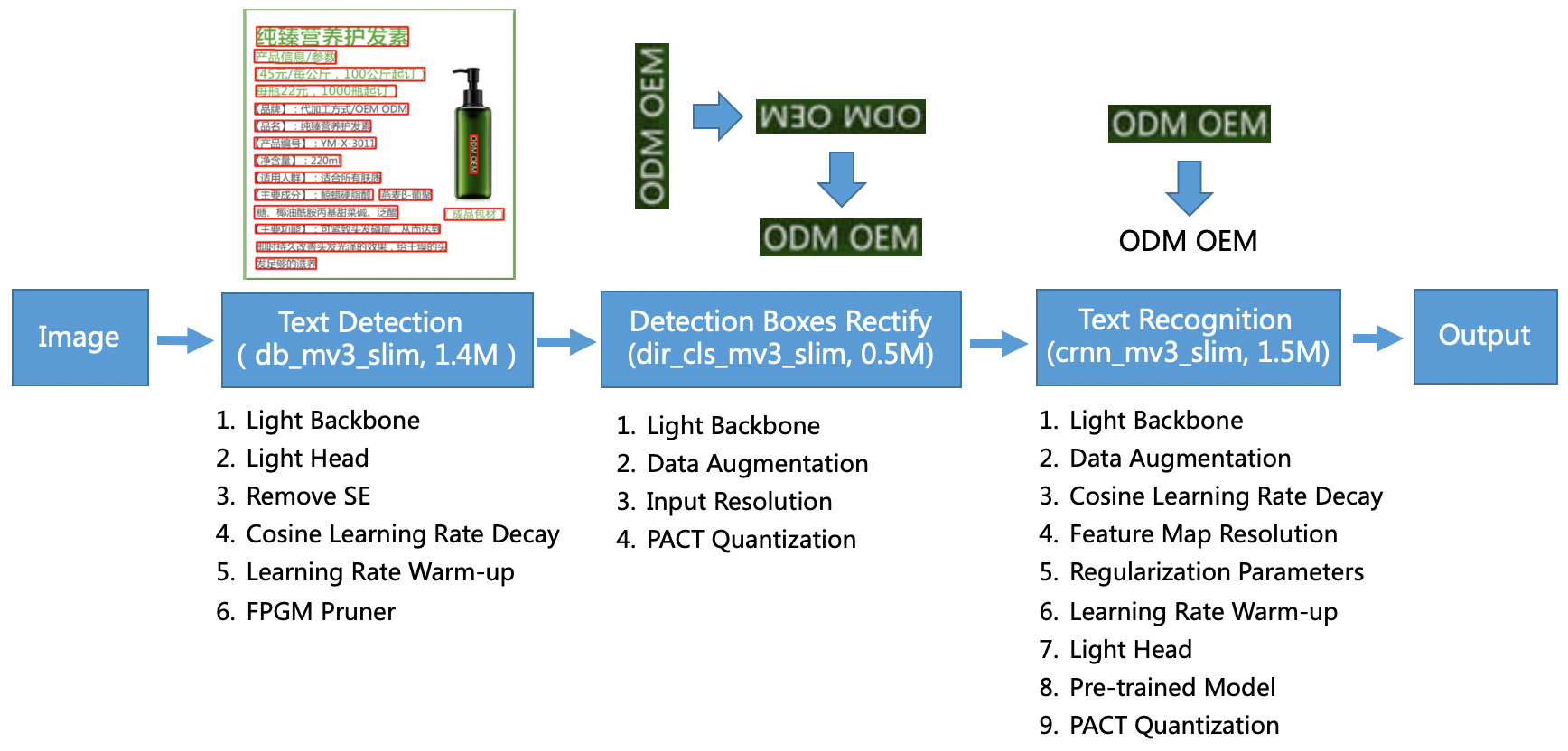
PP-OCR is a practical ultra-lightweight OCR system. It is mainly composed of three parts: DB text detection, detection frame correction and CRNN text recognition. The system adopts 19 effective strategies from 8 aspects including backbone network selection and adjustment, prediction head design, data augmentation, learning rate transformation strategy, regularization parameter selection, pre-training model use, and automatic model tailoring and quantization to optimize and slim down the models of each module. The final results are an ultra-lightweight Chinese and English OCR model with an overall size of 3.5M and a 2.8M English digital OCR model. For more details, please refer to the PP-OCR technical article (https://arxiv.org/abs/2009.09941). Besides, The implementation of the FPGM Pruner and PACT quantization is based on PaddleSlim.
Visualization more
- Chinese OCR model




- English OCR model

- Multilingual OCR model


License
This project is released under Apache 2.0 license
Contribution
We welcome all the contributions to PaddleOCR and appreciate for your feedback very much.
- Many thanks to Khanh Tran and Karl Horky for contributing and revising the English documentation.
- Many thanks to zhangxin for contributing the new visualize function、add .gitgnore and discard set PYTHONPATH manually.
- Many thanks to lyl120117 for contributing the code for printing the network structure.
- Thanks xiangyubo for contributing the handwritten Chinese OCR datasets.
- Thanks authorfu for contributing Android demo and xiadeye contributing iOS demo, respectively.
- Thanks BeyondYourself for contributing many great suggestions and simplifying part of the code style.
- Thanks tangmq for contributing Dockerized deployment services to PaddleOCR and supporting the rapid release of callable Restful API services.
- Thanks lijinhan for contributing a new way, i.e., java SpringBoot, to achieve the request for the Hubserving deployment.
- Thanks Mejans for contributing the Occitan corpus and character set.