1.2 KiB
1.2 KiB
PaddleStructure
pipeline介绍
PaddleStructure 是一个用于复杂板式文字OCR的工具包,流程如下
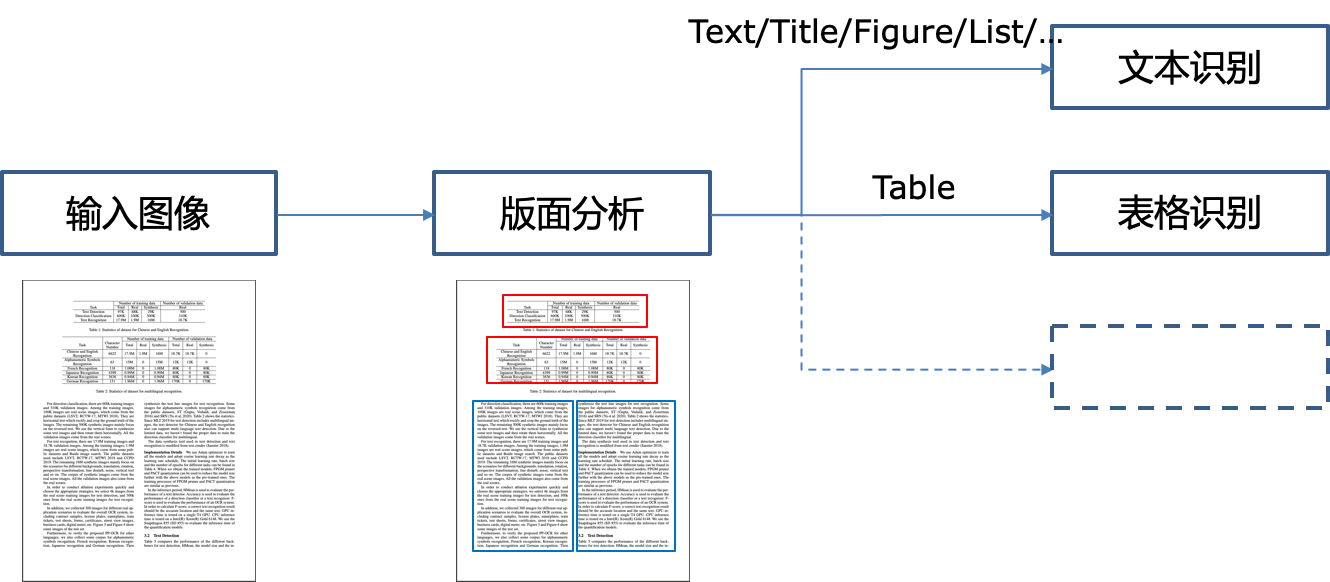
在PaddleStructure中,图片会先经由layoutparser进行版面分析,在版面分析中,会对图片里的区域进行分类,根据根据类别进行对于的ocr流程。
目前layoutparser会输出五个类别:
- Text
- Title
- Figure
- List
- Table
1-4类走传统的OCR流程,5走表格的OCR流程。
LayoutParser
Table OCR
PaddleStructure whl包介绍
使用
- 代码使用
import cv2
from paddlestructure import PaddleStructure,draw_result
table_engine = PaddleStructure(
output='./output/table',
show_log=True)
img_path = '../doc/table/1.png'
img = cv2.imread(img_path)
result = table_engine(img)
for line in result:
print(line)
from PIL import Image
font_path = 'path/tp/PaddleOCR/doc/fonts/simfang.ttf'
image = Image.open(img_path).convert('RGB')
im_show = draw_result(image, result,font_path=font_path)
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')
- 命令行使用
paddlestructure --image_dir=../doc/table/1.png