8.9 KiB
服务器端C++预测
本章节介绍PaddleOCR 模型的的C++部署方法,与之对应的python预测部署方式参考文档。 C++在性能计算上优于python,因此,在大多数CPU、GPU部署场景,多采用C++的部署方式,本节将介绍如何在Linux\Windows (CPU\GPU)环境下配置C++环境并完成 PaddleOCR模型部署。
1. 准备环境
运行准备
- Linux环境,推荐使用docker。
- Windows环境,目前支持基于
Visual Studio 2019 Community进行编译。
- 该文档主要介绍基于Linux环境的PaddleOCR C++预测流程,如果需要在Windows下基于预测库进行C++预测,具体编译方法请参考Windows下编译教程
1.1 编译opencv库
- 首先需要从opencv官网上下载在Linux环境下源码编译的包,以opencv3.4.7为例,下载命令如下。
cd deploy/cpp_infer
wget https://github.com/opencv/opencv/archive/3.4.7.tar.gz
tar -xf 3.4.7.tar.gz
最终可以在当前目录下看到opencv-3.4.7/的文件夹。
- 编译opencv,设置opencv源码路径(
root_path)以及安装路径(install_path)。进入opencv源码路径下,按照下面的方式进行编译。
root_path=your_opencv_root_path
install_path=${root_path}/opencv3
rm -rf build
mkdir build
cd build
cmake .. \
-DCMAKE_INSTALL_PREFIX=${install_path} \
-DCMAKE_BUILD_TYPE=Release \
-DBUILD_SHARED_LIBS=OFF \
-DWITH_IPP=OFF \
-DBUILD_IPP_IW=OFF \
-DWITH_LAPACK=OFF \
-DWITH_EIGEN=OFF \
-DCMAKE_INSTALL_LIBDIR=lib64 \
-DWITH_ZLIB=ON \
-DBUILD_ZLIB=ON \
-DWITH_JPEG=ON \
-DBUILD_JPEG=ON \
-DWITH_PNG=ON \
-DBUILD_PNG=ON \
-DWITH_TIFF=ON \
-DBUILD_TIFF=ON
make -j
make install
其中root_path为下载的opencv源码路径,install_path为opencv的安装路径,make install完成之后,会在该文件夹下生成opencv头文件和库文件,用于后面的OCR代码编译。
最终在安装路径下的文件结构如下所示。
opencv3/
|-- bin
|-- include
|-- lib
|-- lib64
|-- share
1.2 下载或者编译Paddle预测库
- 有2种方式获取Paddle预测库,下面进行详细介绍。
1.2.1 直接下载安装
-
Paddle预测库官网 上提供了不同cuda版本的Linux预测库,可以在官网查看并选择合适的预测库版本(建议选择paddle版本>=2.0.1版本的预测库 )。
-
下载之后使用下面的方法解压。
tar -xf paddle_inference.tgz
最终会在当前的文件夹中生成paddle_inference/的子文件夹。
1.2.2 预测库源码编译
- 如果希望获取最新预测库特性,可以从Paddle github上克隆最新代码,源码编译预测库。
- 可以参考Paddle预测库安装编译说明 的说明,从github上获取Paddle代码,然后进行编译,生成最新的预测库。使用git获取代码方法如下。
git clone https://github.com/PaddlePaddle/Paddle.git
git checkout release/2.1
- 进入Paddle目录后,编译方法如下。
rm -rf build
mkdir build
cd build
cmake .. \
-DWITH_CONTRIB=OFF \
-DWITH_MKL=ON \
-DWITH_MKLDNN=ON \
-DWITH_TESTING=OFF \
-DCMAKE_BUILD_TYPE=Release \
-DWITH_INFERENCE_API_TEST=OFF \
-DON_INFER=ON \
-DWITH_PYTHON=ON
make -j
make inference_lib_dist
更多编译参数选项介绍可以参考文档说明。
- 编译完成之后,可以在
build/paddle_inference_install_dir/文件下看到生成了以下文件及文件夹。
build/paddle_inference_install_dir/
|-- CMakeCache.txt
|-- paddle
|-- third_party
|-- version.txt
其中paddle就是C++预测所需的Paddle库,version.txt中包含当前预测库的版本信息。
2 开始运行
2.1 将模型导出为inference model
- 可以参考模型预测章节,导出inference model,用于模型预测。模型导出之后,假设放在
inference目录下,则目录结构如下。
inference/
|-- det_db
| |--inference.pdiparams
| |--inference.pdmodel
|-- rec_rcnn
| |--inference.pdiparams
| |--inference.pdmodel
2.2 编译PaddleOCR C++预测demo
- 编译命令如下,其中Paddle C++预测库、opencv等其他依赖库的地址需要换成自己机器上的实际地址。
sh tools/build.sh
- 具体的,需要修改
tools/build.sh中环境路径,相关内容如下:
OPENCV_DIR=your_opencv_dir
LIB_DIR=your_paddle_inference_dir
CUDA_LIB_DIR=your_cuda_lib_dir
CUDNN_LIB_DIR=/your_cudnn_lib_dir
其中,OPENCV_DIR为opencv编译安装的地址;LIB_DIR为下载(paddle_inference文件夹)或者编译生成的Paddle预测库地址(build/paddle_inference_install_dir文件夹);CUDA_LIB_DIR为cuda库文件地址,在docker中为/usr/local/cuda/lib64;CUDNN_LIB_DIR为cudnn库文件地址,在docker中为/usr/lib/x86_64-linux-gnu/。注意:以上路径都写绝对路径,不要写相对路径。
- 编译完成之后,会在
build文件夹下生成一个名为ppocr的可执行文件。
运行demo
运行方式:
./build/ppocr <mode> [--param1] [--param2] [...]
其中,mode为必选参数,表示选择的功能,取值范围['det', 'rec', 'system'],分别表示调用检测、识别、检测识别串联(包括方向分类器)。具体命令如下:
1. 只调用检测:
./build/ppocr det \
--det_model_dir=inference/ch_ppocr_mobile_v2.0_det_infer \
--image_dir=../../doc/imgs/12.jpg
2. 只调用识别:
./build/ppocr rec \
--rec_model_dir=inference/ch_ppocr_mobile_v2.0_rec_infer \
--image_dir=../../doc/imgs_words/ch/
3. 调用串联:
# 不使用方向分类器
./build/ppocr system \
--det_model_dir=inference/ch_ppocr_mobile_v2.0_det_infer \
--rec_model_dir=inference/ch_ppocr_mobile_v2.0_rec_infer \
--image_dir=../../doc/imgs/12.jpg
# 使用方向分类器
./build/ppocr system \
--det_model_dir=inference/ch_ppocr_mobile_v2.0_det_infer \
--use_angle_cls=true \
--cls_model_dir=inference/ch_ppocr_mobile_v2.0_cls_infer \
--rec_model_dir=inference/ch_ppocr_mobile_v2.0_rec_infer \
--image_dir=../../doc/imgs/12.jpg
更多参数如下:
- 通用参数
| 参数名称 | 类型 | 默认参数 | 意义 |
|---|---|---|---|
| use_gpu | bool | false | 是否使用GPU |
| gpu_id | int | 0 | GPU id,使用GPU时有效 |
| gpu_mem | int | 4000 | 申请的GPU内存 |
| cpu_math_library_num_threads | int | 10 | CPU预测时的线程数,在机器核数充足的情况下,该值越大,预测速度越快 |
| use_mkldnn | bool | true | 是否使用mkldnn库 |
- 检测模型相关
| 参数名称 | 类型 | 默认参数 | 意义 |
|---|---|---|---|
| det_model_dir | string | - | 检测模型inference model地址 |
| max_side_len | int | 960 | 输入图像长宽大于960时,等比例缩放图像,使得图像最长边为960 |
| det_db_thresh | float | 0.3 | 用于过滤DB预测的二值化图像,设置为0.-0.3对结果影响不明显 |
| det_db_box_thresh | float | 0.5 | DB后处理过滤box的阈值,如果检测存在漏框情况,可酌情减小 |
| det_db_unclip_ratio | float | 1.6 | 表示文本框的紧致程度,越小则文本框更靠近文本 |
| use_polygon_score | bool | false | 是否使用多边形框计算bbox score,false表示使用矩形框计算。矩形框计算速度更快,多边形框对弯曲文本区域计算更准确。 |
| visualize | bool | true | 是否对结果进行可视化,为1时,会在当前文件夹下保存文件名为ocr_vis.png的预测结果。 |
- 方向分类器相关
| 参数名称 | 类型 | 默认参数 | 意义 |
|---|---|---|---|
| use_angle_cls | bool | false | 是否使用方向分类器 |
| cls_model_dir | string | - | 方向分类器inference model地址 |
| cls_thresh | float | 0.9 | 方向分类器的得分阈值 |
- 识别模型相关
| 参数名称 | 类型 | 默认参数 | 意义 |
|---|---|---|---|
| rec_model_dir | string | - | 识别模型inference model地址 |
| char_list_file | string | ../../ppocr/utils/ppocr_keys_v1.txt | 字典文件 |
- PaddleOCR也支持多语言的预测,更多支持的语言和模型可以参考识别文档中的多语言字典与模型部分,如果希望进行多语言预测,只需将修改
char_list_file(字典文件路径)以及rec_model_dir(inference模型路径)字段即可。
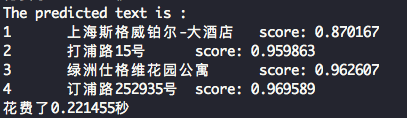
最终屏幕上会输出检测结果如下。
2.3 注意
- 在使用Paddle预测库时,推荐使用2.0.0版本的预测库。