9.6 KiB
English | 简体中文
PP-Structure
PP-Structure是一个可用于复杂文档结构分析和处理的OCR工具包,主要特性如下:
- 支持对图片形式的文档进行版面分析,可以划分文字、标题、表格、图片以及列表5类区域(与Layout-Parser联合使用)
- 支持文字、标题、图片以及列表区域提取为文字字段(与PP-OCR联合使用)
- 支持表格区域进行结构化分析,最终结果输出Excel文件
- 支持python whl包和命令行两种方式,简单易用
- 支持版面分析和表格结构化两类任务自定义训练
1. 效果展示

2. 安装
2.1 安装依赖
- (1) 安装PaddlePaddle
pip3 install --upgrade pip
# GPU安装
python3 -m pip install paddlepaddle-gpu==2.1.1 -i https://mirror.baidu.com/pypi/simple
# CPU安装
python3 -m pip install paddlepaddle==2.1.1 -i https://mirror.baidu.com/pypi/simple
更多需求,请参照安装文档中的说明进行操作。
- (2) 安装 Layout-Parser
pip3 install -U https://paddleocr.bj.bcebos.com/whl/layoutparser-0.0.0-py3-none-any.whl
2.2 安装PaddleOCR(包含PP-OCR和PP-Structure)
- (1) PIP快速安装PaddleOCR whl包(仅预测)
pip install "paddleocr>=2.2" # 推荐使用2.2+版本
- (2) 完整克隆PaddleOCR源码(预测+训练)
【推荐】git clone https://github.com/PaddlePaddle/PaddleOCR
#如果因为网络问题无法pull成功,也可选择使用码云上的托管:
git clone https://gitee.com/paddlepaddle/PaddleOCR
#注:码云托管代码可能无法实时同步本github项目更新,存在3~5天延时,请优先使用推荐方式。
3. PP-Structure 快速开始
3.1 命令行使用(默认参数,极简)
paddleocr --image_dir=../doc/table/1.png --type=structure
3.2 Python脚本使用(自定义参数,灵活)
import os
import cv2
from paddleocr import PPStructure,draw_structure_result,save_structure_res
table_engine = PPStructure(show_log=True)
save_folder = './output/table'
img_path = '../doc/table/1.png'
img = cv2.imread(img_path)
result = table_engine(img)
save_structure_res(result, save_folder,os.path.basename(img_path).split('.')[0])
for line in result:
line.pop('img')
print(line)
from PIL import Image
font_path = '../doc/fonts/simfang.ttf' # PaddleOCR下提供字体包
image = Image.open(img_path).convert('RGB')
im_show = draw_structure_result(image, result,font_path=font_path)
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')
3.3 返回结果说明
PP-Structure的返回结果为一个dict组成的list,示例如下
[
{ 'type': 'Text',
'bbox': [34, 432, 345, 462],
'res': ([[36.0, 437.0, 341.0, 437.0, 341.0, 446.0, 36.0, 447.0], [41.0, 454.0, 125.0, 453.0, 125.0, 459.0, 41.0, 460.0]],
[('Tigure-6. The performance of CNN and IPT models using difforen', 0.90060663), ('Tent ', 0.465441)])
}
]
dict 里各个字段说明如下
| 字段 | 说明 |
|---|---|
| type | 图片区域的类型 |
| bbox | 图片区域的在原图的坐标,分别[左上角x,左上角y,右下角x,右下角y] |
| res | 图片区域的OCR或表格识别结果。 表格: 表格的HTML字符串; OCR: 一个包含各个单行文字的检测坐标和识别结果的元组 |
3.4 参数说明
| 字段 | 说明 | 默认值 |
|---|---|---|
| output | excel和识别结果保存的地址 | ./output/table |
| table_max_len | 表格结构模型预测时,图像的长边resize尺度 | 488 |
| table_model_dir | 表格结构模型 inference 模型地址 | None |
| table_char_type | 表格结构模型所用字典地址 | ../ppocr/utils/dict/table_structure_dict.tx |
大部分参数和paddleocr whl包保持一致,见 whl包文档
运行完成后,每张图片会在output字段指定的目录下有一个同名目录,图片里的每个表格会存储为一个excel,图片区域会被裁剪之后保存下来,excel文件和图片名名为表格在图片里的坐标。
4. PP-Structure Pipeline介绍
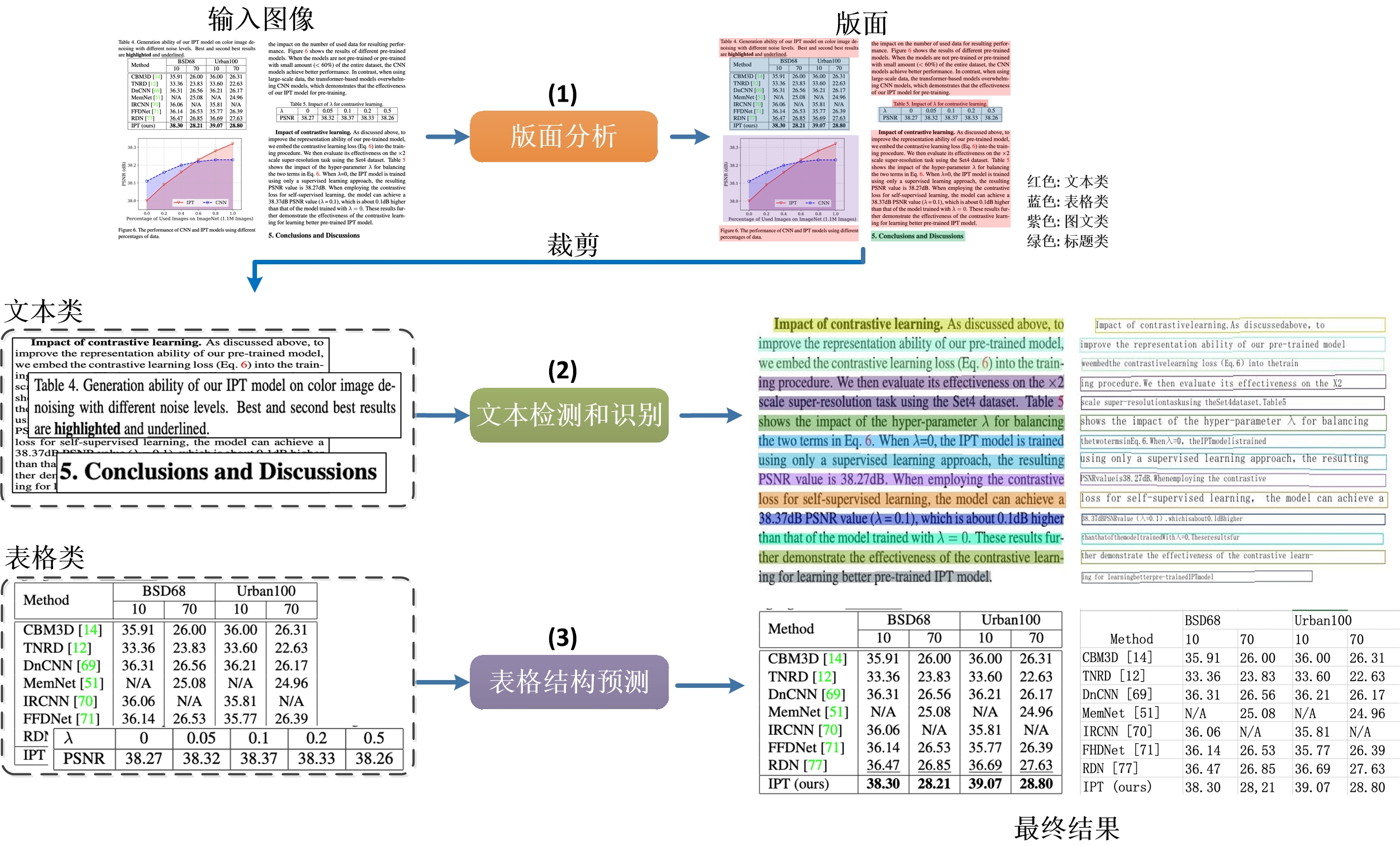
在PP-Structure中,图片会先经由Layout-Parser进行版面分析,在版面分析中,会对图片里的区域进行分类,包括文字、标题、图片、列表和表格5类。对于前4类区域,直接使用PP-OCR完成对应区域文字检测与识别。对于表格类区域,经过表格结构化处理后,表格图片转换为相同表格样式的Excel文件。
4.1 版面分析
版面分析对文档数据进行区域分类,其中包括版面分析工具的Python脚本使用、提取指定类别检测框、性能指标以及自定义训练版面分析模型,详细内容可以参考文档。
4.2 表格识别
表格识别将表格图片转换为excel文档,其中包含对于表格文本的检测和识别以及对于表格结构和单元格坐标的预测,详细说明参考文档
5. 预测引擎推理(与whl包效果相同)
使用如下命令即可完成预测引擎的推理
cd ppstructure
# 下载模型
mkdir inference && cd inference
# 下载超轻量级中文OCR模型的检测模型并解压
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_infer.tar && tar xf ch_ppocr_mobile_v2.0_det_infer.tar
# 下载超轻量级中文OCR模型的识别模型并解压
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_infer.tar && tar xf ch_ppocr_mobile_v2.0_rec_infer.tar
# 下载超轻量级英文表格英寸模型并解压
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_table_structure_infer.tar && tar xf en_ppocr_mobile_v2.0_table_structure_infer.tar
cd ..
python3 predict_system.py --det_model_dir=inference/ch_ppocr_mobile_v2.0_det_infer --rec_model_dir=inference/ch_ppocr_mobile_v2.0_rec_infer --table_model_dir=inference/en_ppocr_mobile_v2.0_table_structure_infer --image_dir=../doc/table/1.png --rec_char_dict_path=../ppocr/utils/ppocr_keys_v1.txt --table_char_dict_path=../ppocr/utils/dict/table_structure_dict.txt --rec_char_type=ch --output=../output/table --vis_font_path=../doc/fonts/simfang.ttf
运行完成后,每张图片会在output字段指定的目录下有一个同名目录,图片里的每个表格会存储为一个excel,图片区域会被裁剪之后保存下来,excel文件和图片名名为表格在图片里的坐标。
Model List
LayoutParser 模型
| 模型名称 | 模型简介 | 下载地址 |
|---|---|---|
| ppyolov2_r50vd_dcn_365e_publaynet | PubLayNet 数据集训练的版面分析模型,可以划分文字、标题、表格、图片以及列表5类区域 | PubLayNet |
| ppyolov2_r50vd_dcn_365e_tableBank_word | TableBank Word 数据集训练的版面分析模型,只能检测表格 | TableBank Word |
| ppyolov2_r50vd_dcn_365e_tableBank_latex | TableBank Latex 数据集训练的版面分析模型,只能检测表格 | TableBank Latex |
OCR和表格识别模型
| 模型名称 | 模型简介 | 推理模型大小 | 下载地址 |
|---|---|---|---|
| ch_ppocr_mobile_slim_v2.0_det | slim裁剪版超轻量模型,支持中英文、多语种文本检测 | 2.6M | 推理模型 / 训练模型 |
| ch_ppocr_mobile_slim_v2.0_rec | slim裁剪量化版超轻量模型,支持中英文、数字识别 | 6M | 推理模型 / 训练模型 |
| en_ppocr_mobile_v2.0_table_det | PubLayNet数据集训练的英文表格场景的文字检测 | 4.7M | 推理模型 / 训练模型 |
| en_ppocr_mobile_v2.0_table_rec | PubLayNet数据集训练的英文表格场景的文字识别 | 6.9M | 推理模型 / 训练模型 |
| en_ppocr_mobile_v2.0_table_structure | PubLayNet数据集训练的英文表格场景的表格结构预测 | 18.6M | 推理模型 / 训练模型 |
如需要使用其他模型,可以在 model_list 下载模型或者使用自己训练好的模型配置到det_model_dir,rec_model_dir,table_model_dir三个字段即可。