|
|
||
|---|---|---|
| .. | ||
| include | ||
| src | ||
| tools | ||
| CMakeLists.txt | ||
| readme.md | ||
| readme_en.md | ||
readme_en.md
Server-side C++ inference
In this tutorial, we will introduce the detailed steps of deploying PaddleOCR ultra-lightweight Chinese detection and recognition models on the server side.
1. Prepare the environment
Environment
- Linux, docker is recommended.
1.1 Compile opencv
- First of all, you need to download the source code compiled package in the Linux environment from the opencv official website. Taking opencv3.4.7 as an example, the download command is as follows.
wget https://github.com/opencv/opencv/archive/3.4.7.tar.gz
tar -xf 3.4.7.tar.gz
Finally, you can see the folder of opencv-3.4.7/ in the current directory.
- Compile opencv, the opencv source path (
root_path) and installation path (install_path) should be set by yourself. Enter the opencv source code path and compile it in the following way.
root_path=your_opencv_root_path
install_path=${root_path}/opencv3
rm -rf build
mkdir build
cd build
cmake .. \
-DCMAKE_INSTALL_PREFIX=${install_path} \
-DCMAKE_BUILD_TYPE=Release \
-DBUILD_SHARED_LIBS=OFF \
-DWITH_IPP=OFF \
-DBUILD_IPP_IW=OFF \
-DWITH_LAPACK=OFF \
-DWITH_EIGEN=OFF \
-DCMAKE_INSTALL_LIBDIR=lib64 \
-DWITH_ZLIB=ON \
-DBUILD_ZLIB=ON \
-DWITH_JPEG=ON \
-DBUILD_JPEG=ON \
-DWITH_PNG=ON \
-DBUILD_PNG=ON \
-DWITH_TIFF=ON \
-DBUILD_TIFF=ON
make -j
make install
Among them, root_path is the downloaded opencv source code path, and install_path is the installation path of opencv. After make install is completed, the opencv header file and library file will be generated in this folder for later OCR source code compilation.
The final file structure under the opencv installation path is as follows.
opencv3/
|-- bin
|-- include
|-- lib
|-- lib64
|-- share
1.2 Compile or download or the Paddle inference library
- There are 2 ways to obtain the Paddle inference library, described in detail below.
1.2.1 Compile from the source code
- If you want to get the latest Paddle inference library features, you can download the latest code from Paddle github repository and compile the inference library from the source code.
- You can refer to [Paddle inference library] (https://www.paddlepaddle.org.cn/documentation/docs/en/advanced_guide/inference_deployment/inference/build_and_install_lib_en.html) to get the Paddle source code from github, and then compile To generate the latest inference library. The method of using git to access the code is as follows.
git clone https://github.com/PaddlePaddle/Paddle.git
- After entering the Paddle directory, the compilation method is as follows.
rm -rf build
mkdir build
cd build
cmake .. \
-DWITH_CONTRIB=OFF \
-DWITH_MKL=ON \
-DWITH_MKLDNN=ON \
-DWITH_TESTING=OFF \
-DCMAKE_BUILD_TYPE=Release \
-DWITH_INFERENCE_API_TEST=OFF \
-DON_INFER=ON \
-DWITH_PYTHON=ON
make -j
make inference_lib_dist
For more compilation parameter options, please refer to the official website of the Paddle C++ inference library:https://www.paddlepaddle.org.cn/documentation/docs/en/advanced_guide/inference_deployment/inference/build_and_install_lib_en.html.
- After the compilation process, you can see the following files in the folder of
build/fluid_inference_install_dir/.
build/fluid_inference_install_dir/
|-- CMakeCache.txt
|-- paddle
|-- third_party
|-- version.txt
Among them, paddle is the Paddle library required for C++ prediction later, and version.txt contains the version information of the current inference library.
1.2.2 Direct download and installation
-
Different cuda versions of the Linux inference library (based on GCC 4.8.2) are provided on the Paddle inference library official website. You can view and select the appropriate version of the inference library on the official website.
-
After downloading, use the following method to uncompress.
tar -xf fluid_inference.tgz
Finally you can see the following files in the folder of fluid_inference/.
2. Compile and run the demo
2.1 Export the inference model
- You can refer to Model inference,export the inference model. After the model is exported, assuming it is placed in the
inferencedirectory, the directory structure is as follows.
inference/
|-- det_db
| |--model
| |--params
|-- rec_rcnn
| |--model
| |--params
2.2 Compile PaddleOCR C++ inference demo
- The compilation commands are as follows. The addresses of Paddle C++ inference library, opencv and other Dependencies need to be replaced with the actual addresses on your own machines.
sh tools/build.sh
具体地,tools/build.sh中内容如下。
OPENCV_DIR=your_opencv_dir
LIB_DIR=your_paddle_inference_dir
CUDA_LIB_DIR=your_cuda_lib_dir
CUDNN_LIB_DIR=your_cudnn_lib_dir
BUILD_DIR=build
rm -rf ${BUILD_DIR}
mkdir ${BUILD_DIR}
cd ${BUILD_DIR}
cmake .. \
-DPADDLE_LIB=${LIB_DIR} \
-DWITH_MKL=ON \
-DDEMO_NAME=ocr_system \
-DWITH_GPU=OFF \
-DWITH_STATIC_LIB=OFF \
-DUSE_TENSORRT=OFF \
-DOPENCV_DIR=${OPENCV_DIR} \
-DCUDNN_LIB=${CUDNN_LIB_DIR} \
-DCUDA_LIB=${CUDA_LIB_DIR} \
make -j
OPENCV_DIR is the opencv installation path; LIB_DIR is the download (fluid_inference folder) or the generated Paddle inference library path (build/fluid_inference_install_dir folder); CUDA_LIB_DIR is the cuda library file path, in docker; it is /usr/local/cuda/lib64; CUDNN_LIB_DIR is the cudnn library file path, in docker it is /usr/lib/x86_64-linux-gnu/.
- After the compilation is completed, an executable file named
ocr_systemwill be generated in thebuildfolder.
Run the demo
- Execute the following command to complete the OCR recognition and detection of an image.
sh tools/run.sh
The detection results will be shown on the screen, which is as follows.
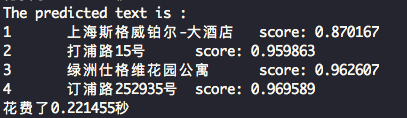
2.3 Note
MKLDNNis disabled by default for C++ inference (use_mkldnnintools/config.txtis set to 0), if you need to use MKLDNN for inference acceleration, you need to modifyuse_mkldnnto 1, and use the latest version of the Paddle source code to compile the inference library. When using MKLDNN for CPU prediction, if multiple images are predicted at the same time, there will be a memory leak problem (the problem is not present if MKLDNN is disabled). The problem is currently being fixed, and the temporary solution is: when predicting multiple pictures, Re-initialize the recognition (CRNNRecognizer) and detection class (DBDetector) every 30 pictures or so.