Signed-off-by: Forest-L <lilin@yunify.com> |
||
|---|---|---|
| .github/workflows | ||
| checks | ||
| cmd | ||
| config | ||
| docs | ||
| examples | ||
| pkg | ||
| test | ||
| .gitignore | ||
| LICENSE | ||
| Makefile | ||
| OWNERS | ||
| README.md | ||
| go.mod | ||
| go.sum | ||
| main.go | ||
README.md
Kubeye
Kubeye aims to find various problems on Kubernetes, such as application misconfiguration(using Polaris), cluster components unhealthy and node problems(using Node-Problem-Detector). Besides predefined rules, it also supports custom defined rules.
Architecture
Kubeye gets cluster diagnostic data by calling the Kubernetes API, by regular matching of key error messages in logs and by rule matching of container syntax. See Architecture for details.
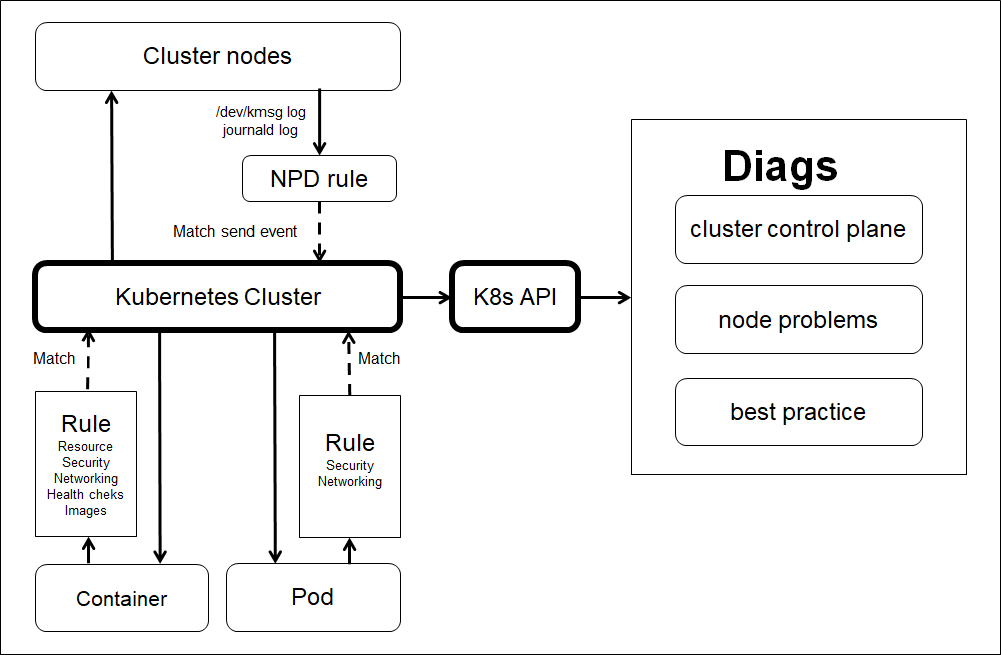
How to use
-
Install Kubeye on your machine
-
Download pre built executables from Releases.
-
Or you can build from source code
git clone https://github.com/kubesphere/kubeye.git cd kubeye make install -
-
[Optional] Install Node-problem-Detector
Note: This line will install npd on your cluster, only required if you want detailed report.
ke install npd
- Run kubeye
root@node1:# ke diag
NODENAME SEVERITY HEARTBEATTIME REASON MESSAGE
node18 Fatal 2020-11-19T10:32:03+08:00 NodeStatusUnknown Kubelet stopped posting node status.
node19 Fatal 2020-11-19T10:31:37+08:00 NodeStatusUnknown Kubelet stopped posting node status.
node2 Fatal 2020-11-19T10:31:14+08:00 NodeStatusUnknown Kubelet stopped posting node status.
node3 Fatal 2020-11-27T17:36:53+08:00 KubeletNotReady Container runtime not ready: RuntimeReady=false reason:DockerDaemonNotReady message:docker: failed to get docker version: Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?
NAME SEVERITY TIME MESSAGE
scheduler Fatal 2020-11-27T17:09:59+08:00 Get http://127.0.0.1:10251/healthz: dial tcp 127.0.0.1:10251: connect: connection refused
etcd-0 Fatal 2020-11-27T17:56:37+08:00 Get https://192.168.13.8:2379/health: dial tcp 192.168.13.8:2379: connect: connection refused
NAMESPACE SEVERITY PODNAME EVENTTIME REASON MESSAGE
default Warning node3.164b53d23ea79fc7 2020-11-27T17:37:34+08:00 ContainerGCFailed rpc error: code = Unknown desc = Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?
default Warning node3.164b553ca5740aae 2020-11-27T18:03:31+08:00 FreeDiskSpaceFailed failed to garbage collect required amount of images. Wanted to free 5399374233 bytes, but freed 416077545 bytes
default Warning nginx-b8ffcf679-q4n9v.16491643e6b68cd7 2020-11-27T17:09:24+08:00 Failed Error: ImagePullBackOff
default Warning node3.164b5861e041a60e 2020-11-27T19:01:09+08:00 SystemOOM System OOM encountered, victim process: stress, pid: 16713
default Warning node3.164b58660f8d4590 2020-11-27T19:01:27+08:00 OOMKilling Out of memory: Kill process 16711 (stress) score 205 or sacrifice child Killed process 16711 (stress), UID 0, total-vm:826516kB, anon-rss:819296kB, file-rss:0kB, shmem-rss:0kB
insights-agent Warning workloads-1606467120.164b519ca8c67416 2020-11-27T16:57:05+08:00 DeadlineExceeded Job was active longer than specified deadline
kube-system Warning calico-node-zvl9t.164b3dc50580845d 2020-11-27T17:09:35+08:00 DNSConfigForming Nameserver limits were exceeded, some nameservers have been omitted, the applied nameserver line is: 100.64.11.3 114.114.114.114 119.29.29.29
kube-system Warning kube-proxy-4bnn7.164b3dc4f4c4125d 2020-11-27T17:09:09+08:00 DNSConfigForming Nameserver limits were exceeded, some nameservers have been omitted, the applied nameserver line is: 100.64.11.3 114.114.114.114 119.29.29.29
kube-system Warning nodelocaldns-2zbhh.164b3dc4f42d358b 2020-11-27T17:09:14+08:00 DNSConfigForming Nameserver limits were exceeded, some nameservers have been omitted, the applied nameserver line is: 100.64.11.3 114.114.114.114 119.29.29.29
NAMESPACE SEVERITY NAME KIND TIME MESSAGE
kube-system Warning node-problem-detector DaemonSet 2020-11-27T17:09:59+08:00 [livenessProbeMissing runAsPrivileged]
kube-system Warning calico-node DaemonSet 2020-11-27T17:09:59+08:00 [runAsPrivileged cpuLimitsMissing]
kube-system Warning nodelocaldns DaemonSet 2020-11-27T17:09:59+08:00 [cpuLimitsMissing runAsPrivileged]
default Warning nginx Deployment 2020-11-27T17:09:59+08:00 [cpuLimitsMissing livenessProbeMissing tagNotSpecified]
insights-agent Warning workloads CronJob 2020-11-27T17:09:59+08:00 [livenessProbeMissing]
insights-agent Warning cronjob-executor Job 2020-11-27T17:09:59+08:00 [livenessProbeMissing]
kube-system Warning calico-kube-controllers Deployment 2020-11-27T17:09:59+08:00 [cpuLimitsMissing livenessProbeMissing]
kube-system Warning coredns Deployment 2020-11-27T17:09:59+08:00 [cpuLimitsMissing]
You can refer to the FAQ content to optimize your cluster.
What kubeye can do
- Kubeye can find problems of your cluster control plane, including kube-apiserver/kube-controller-manager/etcd, etc.
- Kubeye helps you detect all kinds of node problems, including memory/cpu/disk pressure, unexpected kernel error logs, etc.
- Kubeye validates your workloads yaml specs against industry best practice, helps you make your cluster stable.
Checklist
| YES/NO | CHECK ITEM | Description |
|---|---|---|
| ✅ | ETCDHealthStatus | if etcd is up and running normally |
| ✅ | ControllerManagerHealthStatus | if kubernetes kube-controller-manager is up and running normally. |
| ✅ | SchedulerHealthStatus | if kubernetes kube-scheduler |
| ✅ | NodeMemory | if node memory usage is above threshold |
| ✅ | DockerHealthStatus | if docker is up and running |
| ✅ | NodeDisk | if node disk usage is above given threshold |
| ✅ | KubeletHealthStatus | if kubelet is active and running normally |
| ✅ | NodeCPU | if node cpu usage is above the given threshold |
| ✅ | NodeCorruptOverlay2 | Overlay2 is not available |
| ✅ | NodeKernelNULLPointer | the node displays NotReady |
| ✅ | NodeDeadlock | A deadlock is a phenomenon in which two or more processes are waiting for each other as they compete for resources |
| ✅ | NodeOOM | Monitor processes that consume too much memory, especially those that consume a lot of memory very quickly, and the kernel kill them to prevent them from running out of memory |
| ✅ | NodeExt4Error | Ext4 mount error |
| ✅ | NodeTaskHung | Check to see if there is a process in state D for more than 120s |
| ✅ | NodeUnregisterNetDevice | Check corresponding net |
| ✅ | NodeCorruptDockerImage | Check docker image |
| ✅ | NodeAUFSUmountHung | Check storage |
| ✅ | NodeDockerHung | Docker hung, you can check docker log |
| ✅ | PodSetLivenessProbe | if livenessProbe set for every container in a pod |
| ✅ | PodSetTagNotSpecified | The mirror address does not declare tag or tag is latest |
| ✅ | PodSetRunAsPrivileged | Running a pod in a privileged mode means that the pod can access the host’s resources and kernel capabilities |
| ✅ | PodSetImagePullBackOff | Pod can't pull the image properly, so it can be pulled manually on the corresponding node |
| ✅ | PodSetImageRegistry | Checks if the image form is at the beginning of the corresponding harbor |
| ✅ | PodSetCpuLimitsMissing | No CPU Resource limit was declared |
| ✅ | PodNoSuchFileOrDirectory | Go into the container to see if the corresponding file exists |
| ✅ | PodIOError | This is usually due to file IO performance bottlenecks |
| ✅ | PodNoSuchDeviceOrAddress | Check corresponding net |
| ✅ | PodInvalidArgument | Check the storage |
| ✅ | PodDeviceOrResourceBusy | Check corresponding dirctory and PID |
| ✅ | PodFileExists | Check for existing files |
| ✅ | PodTooManyOpenFiles | The number of file /socket connections opened by the program exceeds the system set value |
| ✅ | PodNoSpaceLeftOnDevice | Check for disk and inode usage |
| ✅ | NodeApiServerExpiredPeriod | ApiServer certificate expiration date less than 30 days will be checked |
| ✅ | PodSetCpuRequestsMissing | The CPU Resource Request value was not declared |
| ✅ | PodSetHostIPCSet | Set the hostIP |
| ✅ | PodSetHostNetworkSet | Set the hostNetwork |
| ✅ | PodHostPIDSet | Set the hostPID |
| ✅ | PodMemoryRequestsMiss | No memory Resource Request value is declared |
| ✅ | PodSetHostPort | Set the hostPort |
| ✅ | PodSetMemoryLimitsMissing | No memory Resource limit value is declared |
| ✅ | PodNotReadOnlyRootFiles | The file system is not set to read-only |
| ✅ | PodSetPullPolicyNotAlways | The mirror pull strategy is not always |
| ✅ | PodSetRunAsRootAllowed | Executed as a root account |
| ✅ | PodDangerousCapabilities | You have the dangerous option in capabilities such as ALL/SYS_ADMIN/NET_ADMIN |
| ✅ | PodlivenessProbeMissing | ReadinessProbe was not declared |
| ✅ | privilegeEscalationAllowed | Privilege escalation is allowed |
| NodeNotReadyAndUseOfClosedNetworkConnection | http2-max-streams-per-connection | |
| NodeNotReady | Failed to start ContainerManager Cannot set property TasksAccounting, or unknown property |
unmarked items are under heavy development
Add your own check rules
Add custom npd rule
- Install NPD with
ke install npd - Edit configmap kube-system/node-problem-detector-config with kubectl,
kubectl edit cm -n kube-system node-problem-detector-config
- Add exception log information under the rule of configMap, rules follow regular expressions.
Fault with your own custom best practice rules
- Prepare a rule yaml, for example, the following rule will validate your pod spec to make sure image are only from authorized registries.
checks:
imageFromUnauthorizedRegistry: warning
customChecks:
imageFromUnauthorizedRegistry:
promptMessage: When the corresponding rule does not match. Show that image from an unauthorized registry.
category: Images
target: Container
schema:
'$schema': http://json-schema.org/draft-07/schema
type: object
properties:
image:
type: string
not:
pattern: ^quay.io
- Save the above rule as a yaml, for example,
rule.yaml. - Run kubeye with
rule.yaml
root:# ke diag -f rule.yaml --kubeconfig ~/.kube/config
NAMESPACE SEVERITY NAME KIND TIME MESSAGE
default Warning nginx Deployment 2020-11-27T17:18:31+08:00 [imageFromUnauthorizedRegistry]
kube-system Warning node-problem-detector DaemonSet 2020-11-27T17:18:31+08:00 [livenessProbeMissing runAsPrivileged]
kube-system Warning calico-node DaemonSet 2020-11-27T17:18:31+08:00 [cpuLimitsMissing runAsPrivileged]
kube-system Warning calico-kube-controllers Deployment 2020-11-27T17:18:31+08:00 [cpuLimitsMissing livenessProbeMissing]
kube-system Warning nodelocaldns DaemonSet 2020-11-27T17:18:31+08:00 [runAsPrivileged cpuLimitsMissing]
default Warning nginx Deployment 2020-11-27T17:18:31+08:00 [livenessProbeMissing cpuLimitsMissing]
kube-system Warning coredns Deployment 2020-11-27T17:18:31+08:00 [cpuLimitsMissing]