5.0 KiB

介绍
Nightingale is an enterprise-level cloud-native monitoring system, which can be used as drop-in replacement of Prometheus for alerting and management.
夜莺是一款开源的云原生监控系统,采用 All-In-One 的设计,提供企业级的功能特性,开箱即用的产品体验。推荐升级您的
Prometheus+AlertManager+Grafana组合方案到夜莺。
- 内置丰富的Dashboard、好用实用的告警管理、自定义视图、故障自愈;
- Dashboard和告警策略支持一键导入,详细的指标分类和解释;
- 支持多 Prometheus 数据源管理,以一个集中的视图来管理所有的告警和dashboard;
- 支持 Prometheus、M3DB、VictoriaMetrics、Influxdb、TDEngine 等多种时序库作为存储方案;
- 原生支持 PromQL;
- 支持 Exporter 作为数据采集方案;
- 支持 Telegraf 作为监控数据采集方案;
- 支持对接 Grafana 作为补充可视化方案;
如果您在使用 Prometheus 过程中,有以下的一个或者多个需求场景,推荐您升级到夜莺:
- Prometheus、Alertmanager、Grafana 等多个系统较为割裂,缺乏统一视图,无法开箱即用;
- 通过修改配置文件来管理 Prometheus、Alertmanager 的方式,学习曲线大,协同有难度;
- 数据量过大而无法扩展您的 Prometheus 集群;
- 生产环境运行多套 Prometheus 集群,面临管理和使用成本高的问题;
如果您在使用Zabbix,有以下的场景,推荐您升级到夜莺:
- 监控的数据量太大,希望有更好的扩展解决方案;
- 学习曲线高,多人多团队模式下,希望有更好的协同使用效率;
- 微服务和云原生架构下,监控数据的生命周期多变、监控数据维度基数高,Zabbix数据模型不易适配;
如果您在使用open-falcon,我们更推荐您升级到夜莺:
- 关于open-falcon和夜莺的详细介绍,请参考阅读云原生监控的十个特点和趋势。
资料链接
产品演示

架构介绍

Nightingale 可以接收各种采集器上报的监控数据,转存到时序库(可以支持Prometheus、M3DB、VictoriaMetrics、Thanos等),并提供告警规则、屏蔽规则、订阅规则的配置能力,提供监控数据的查看能力,提供告警自愈机制(告警触发之后自动回调某个webhook地址或者执行某个脚本),提供历史告警事件的存储管理、分组查看的能力。
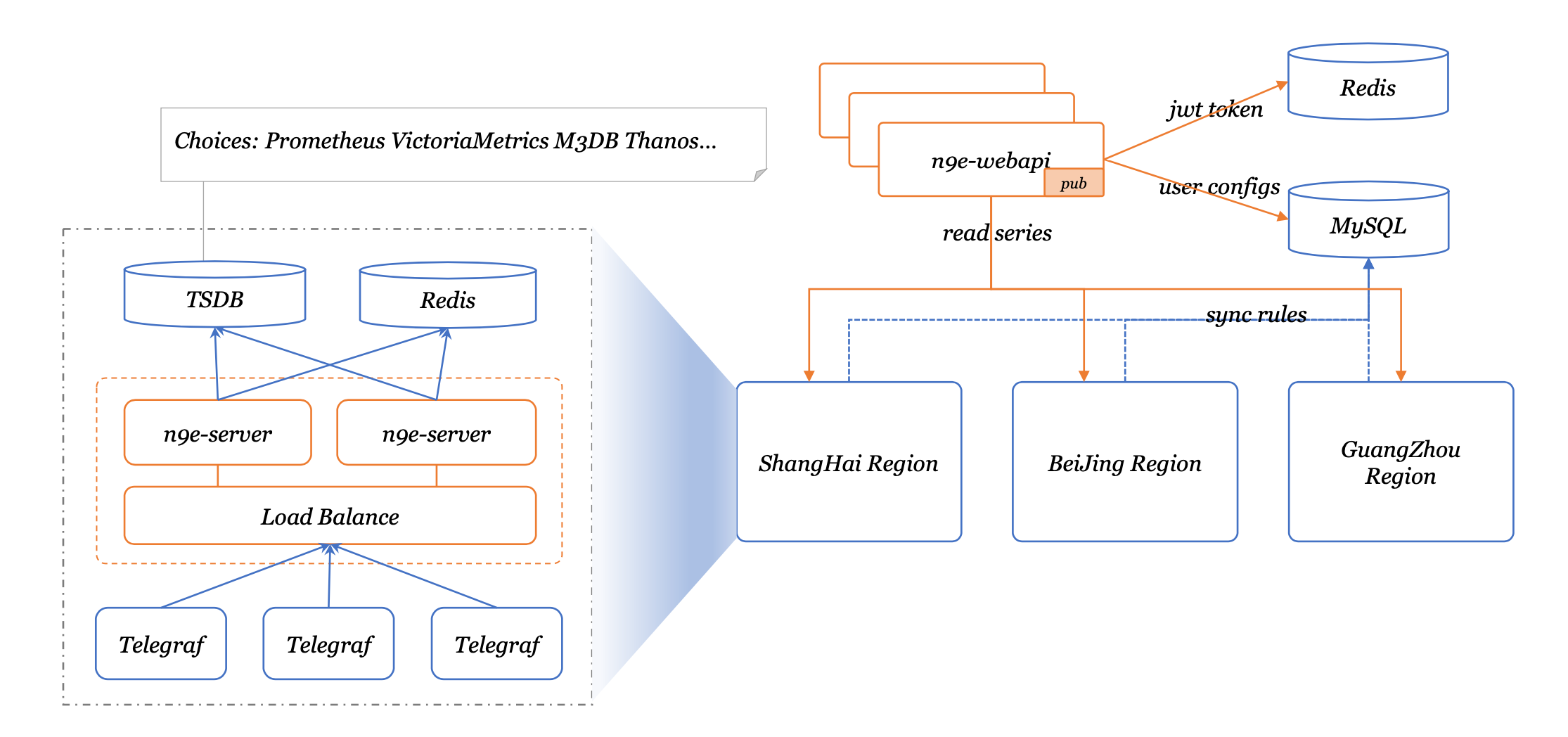
夜莺 v5 版本的设计非常简单,核心是 server 和 webapi 两个模块,webapi 无状态,放到中心端,承接前端请求,将用户配置写入数据库;server 是告警引擎和数据转发模块,一般随着时序库走,一个时序库就对应一套 server,每套 server 可以只用一个实例,也可以多个实例组成集群,server 可以接收 Categraf、Telegraf、Grafana-Agent、Datadog-Agent、Falcon-Plugins 上报的数据,写入后端时序库,周期性从数据库同步告警规则,然后查询时序库做告警判断。每套 server 依赖一个 redis。

有些朋友可能会觉得单机版本的 Prometheus 性能不够或容灾较差,想要集群版本的时序库,我们推荐使用 VictoriaMetrics,VictoriaMetrics 架构较为简单,易于部署和运维,架构图如上,当然,VictoriaMetrics 更详尽的文档,还请参考其官网。
如何参与
我们欢迎您以各种方式参与到夜莺开源项目和开源社区中来,工作包括不限于:
- 反馈使用中遇到的问题和Bug => github issue
- 补充和完善文档 => n9e.github.io
- 分享您在使用夜莺监控过程中的最佳实践和经验心得 => 文章分享
- 提交代码,让夜莺监控更快、更稳、更好用 => github pull request
联系我们
- 加入微信群组,请先添加微信:borgmon 备注:夜莺加群
- 推荐您关注夜莺监控公众号,及时获取相关产品动态
