4.9 KiB
Deep Voice 3
PaddlePaddle dynamic graph implementation of Deep Voice 3, a convolutional network based text-to-speech generative model. The implementation is based on Deep Voice 3: Scaling Text-to-Speech with Convolutional Sequence Learning.
We implement Deep Voice 3 using Paddle Fluid with dynamic graph, which is convenient for building flexible network architectures.
Dataset
We experiment with the LJSpeech dataset. Download and unzip LJSpeech.
wget https://data.keithito.com/data/speech/LJSpeech-1.1.tar.bz2
tar xjvf LJSpeech-1.1.tar.bz2
Model Architecture
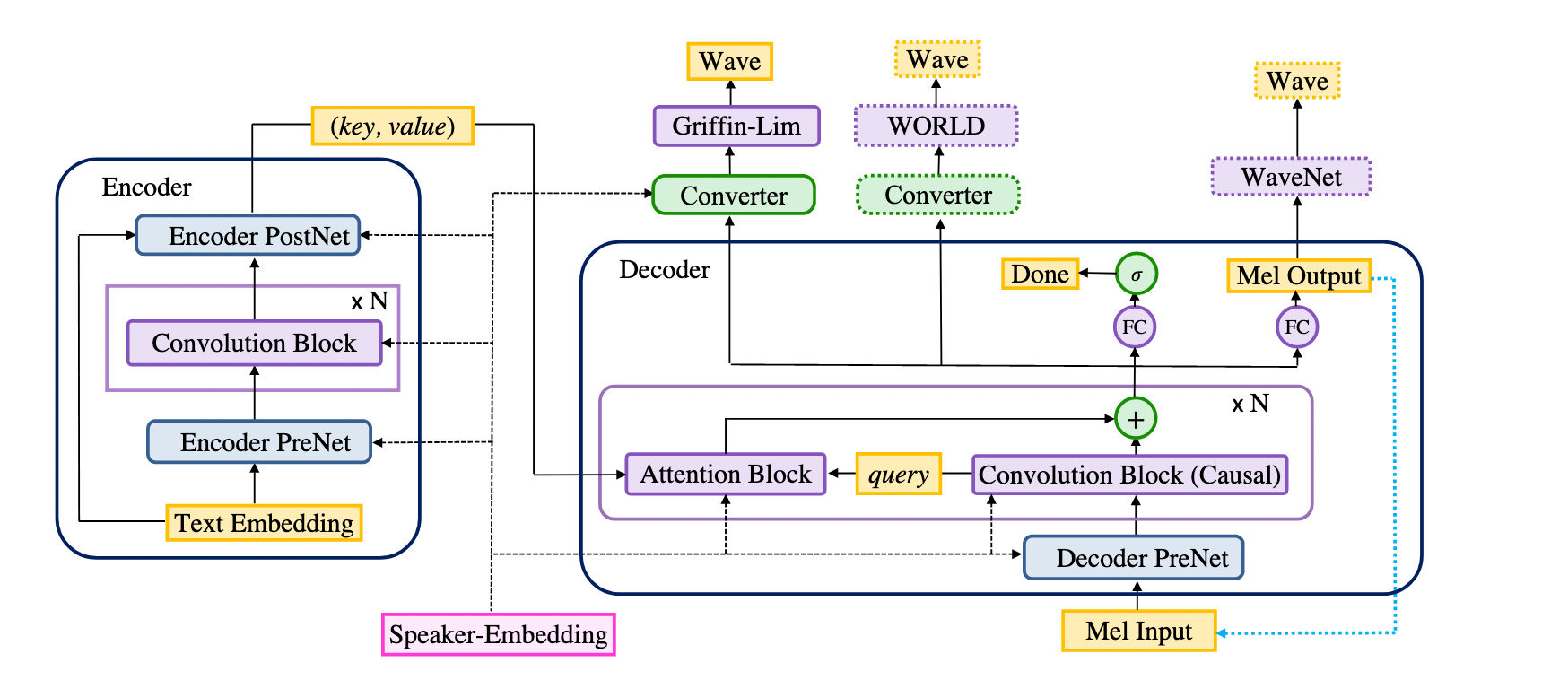
The model consists of an encoder, a decoder and a converter (and a speaker embedding for multispeaker models). The encoder and the decoder together form the seq2seq part of the model, and the converter forms the postnet part.
Project Structure
├── config/
├── synthesize.py
├── data.py
├── preprocess.py
├── clip.py
├── train.py
└── vocoder.py
Preprocess
Preprocess to dataset with preprocess.py.
usage: preprocess.py [-h] --config CONFIG --input INPUT --output OUTPUT
preprocess ljspeech dataset and save it.
optional arguments:
-h, --help show this help message and exit
--config CONFIG config file
--input INPUT data path of the original data
--output OUTPUT path to save the preprocessed dataset
example code:
python preprocess.py --config=configs/ljspeech.yaml --input=LJSpeech-1.1/ --output=data/ljspeech
Train
Train the model using train.py, follow the usage displayed by python train.py --help.
usage: train.py [-h] --config CONFIG --input INPUT
train a Deep Voice 3 model with LJSpeech
optional arguments:
-h, --help show this help message and exit
--config CONFIG config file
--input INPUT data path of the original data
example code:
CUDA_VISIBLE_DEVICES=0 python train.py --config=configs/ljspeech.yaml --input=data/ljspeech
It would create a runs folder, outputs for each run is saved in a seperate folder in runs, whose name is the time joined with hostname. Inside this filder, tensorboard log, parameters and optimizer states are saved. Parameters(*.pdparams) and optimizer states(*.pdopt) are named by the step when they are saved.
runs/Jul07_09-39-34_instance-mqcyj27y-4/
├── checkpoint
├── events.out.tfevents.1594085974.instance-mqcyj27y-4
├── step-1000000.pdopt
├── step-1000000.pdparams
├── step-100000.pdopt
├── step-100000.pdparams
...
Since we use waveflow to synthesize audio while training, so download the trained waveflow model and extract it in current directory before training.
wget https://paddlespeech.bj.bcebos.com/Parakeet/waveflow_res128_ljspeech_ckpt_1.0.zip
unzip waveflow_res128_ljspeech_ckpt_1.0.zip
Visualization
You can visualize training losses, check the attention and listen to the synthesized audio when training with teacher forcing.
example code:
tensorboard --logdir=runs/ --host=$HOSTNAME --port=8000
Synthesis
usage: synthesize from a checkpoint [-h] --config CONFIG --input INPUT
--output OUTPUT --checkpoint CHECKPOINT
--monotonic_layers MONOTONIC_LAYERS
[--vocoder {griffin-lim,waveflow}]
optional arguments:
-h, --help show this help message and exit
--config CONFIG config file
--input INPUT text file to synthesize
--output OUTPUT path to save audio
--checkpoint CHECKPOINT
data path of the checkpoint
--monotonic_layers MONOTONIC_LAYERS
monotonic decoder layers' indices(start from 1)
--vocoder {griffin-lim,waveflow}
vocoder to use
synthesize.py is used to synthesize several sentences in a text file.
--monotonic_layers is the index of the decoders layer that manifest monotonic diagonal attention. You can get monotonic layers by inspecting tensorboard logs. Mind that the index starts from 1. The layers that manifest monotonic diagonal attention are stable for a model during training and synthesizing, but differ among different runs. So once you get the indices of monotonic layers by inspecting tensorboard log, you can use them at synthesizing. Note that only decoder layers that show strong diagonal attention should be considerd.
--vocoder is the vocoder to use. Current supported values are "waveflow" and "griffin-lim". Default value is "waveflow".
example code:
CUDA_VISIBLE_DEVICES=2 python synthesize.py \
--config configs/ljspeech.yaml \
--input sentences.txt \
--output outputs/ \
--checkpoint runs/Jul07_09-39-34_instance-mqcyj27y-4/step-1320000 \
--monotonic_layers "5,6" \
--vocoder waveflow