4.3 KiB
TransformerTTS
PaddlePaddle dynamic graph implementation of TransformerTTS, a neural TTS with Transformer. The implementation is based on Neural Speech Synthesis with Transformer Network.
Dataset
We experiment with the LJSpeech dataset. Download and unzip LJSpeech.
wget https://data.keithito.com/data/speech/LJSpeech-1.1.tar.bz2
tar xjvf LJSpeech-1.1.tar.bz2
Model Architecture
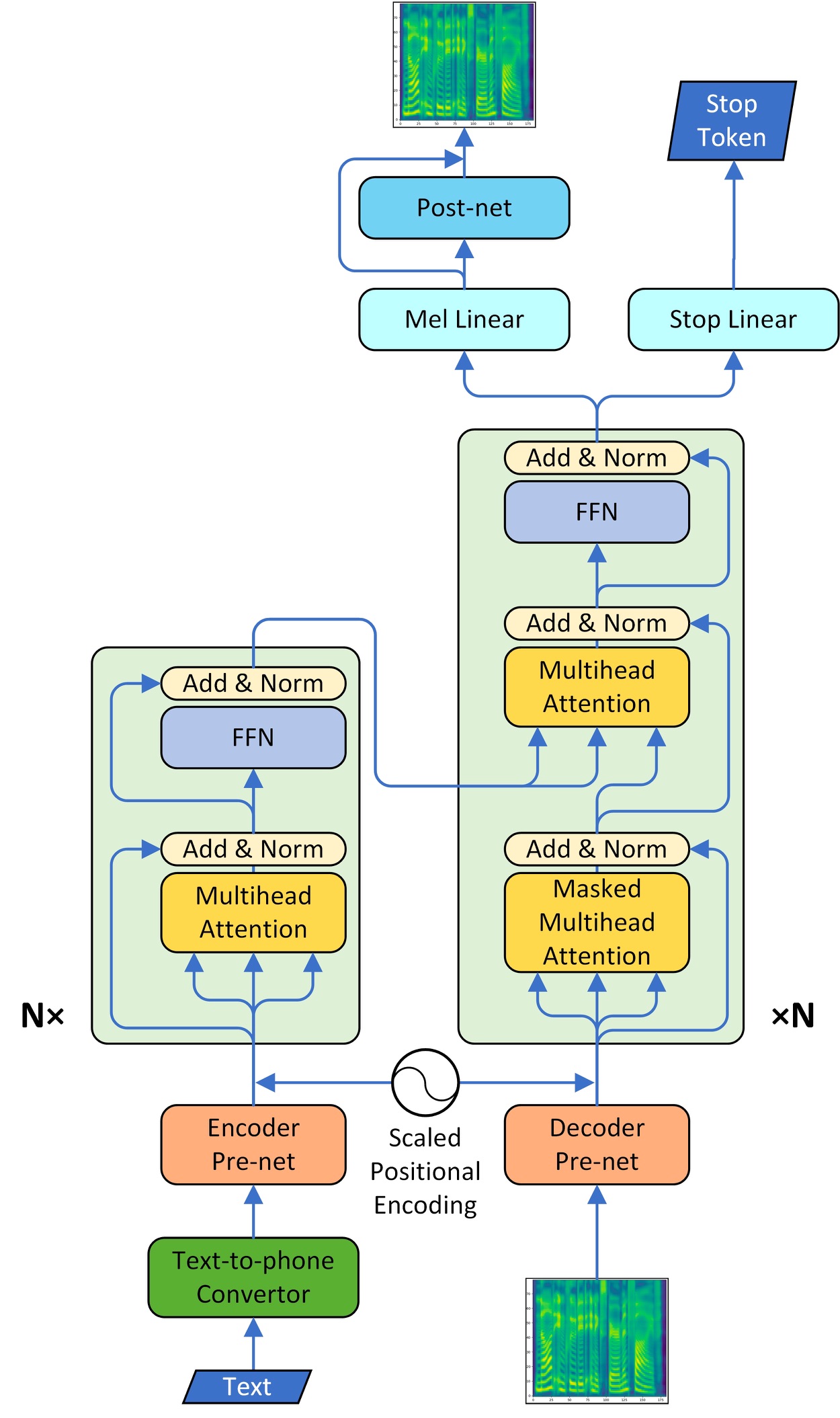
The model adopts the multi-head attention mechanism to replace the RNN structures and also the original attention mechanism in Tacotron2. The model consists of two main parts, encoder and decoder. We also implement the CBHG model of Tacotron as the vocoder part and convert the spectrogram into raw wave using Griffin-Lim algorithm.
Project Structure
├── config # yaml configuration files
├── data.py # dataset and dataloader settings for LJSpeech
├── synthesis.py # script to synthesize waveform from text
├── train_transformer.py # script for transformer model training
├── train_vocoder.py # script for vocoder model training
Saving & Loading
train_transformer.py and train_vocoer.py have 3 arguments in common, --checkpoint, --iteration and --output.
-
--outputis the directory for saving results. During training, checkpoints are saved in${output}/checkpointsand tensorboard logs are saved in${output}/log. During synthesis, results are saved in${output}/samplesand tensorboard log is save in${output}/log. -
--checkpointis the path of a checkpoint and--iterationis the target step. They are used to load checkpoints in the following way.-
If
--checkpointis provided, the checkpoint specified by--checkpointis loaded. -
If
--checkpointis not provided, we try to load the checkpoint of the target step specified by--iterationfrom the${output}/checkpoints/directory, e.g. if given--iteration 120000, the checkpoint${output}/checkpoints/step-120000.*will be load. -
If both
--checkpointand--iterationare not provided, we try to load the latest checkpoint from${output}/checkpoints/directory.
-
Train Transformer
TransformerTTS model can be trained by running train_transformer.py.
python train_transformer.py \
--use_gpu=1 \
--data=${DATAPATH} \
--output=${OUTPUTPATH} \
--config='configs/ljspeech.yaml' \
Or you can run the script file directly.
sh train_transformer.sh
If you want to train on multiple GPUs, you must start training in the following way.
CUDA_VISIBLE_DEVICES=0,1,2,3
python -m paddle.distributed.launch --selected_gpus=0,1,2,3 --log_dir ./mylog train_transformer.py \
--use_gpu=1 \
--data=${DATAPATH} \
--output=${OUTPUTPATH} \
--config='configs/ljspeech.yaml' \
If you wish to resume from an existing model, See Saving-&-Loading for details of checkpoint loading.
Note: In order to ensure the training effect, we recommend using multi-GPU training to enlarge the batch size, and at least 16 samples in single batch per GPU.
For more help on arguments
python train_transformer.py --help.
Synthesis
After training the TransformerTTS, audio can be synthesized by running synthesis.py.
python synthesis.py \
--use_gpu=0 \
--output=${OUTPUTPATH} \
--config='configs/ljspeech.yaml' \
--checkpoint_transformer=${CHECKPOINTPATH} \
--vocoder='griffin-lim' \
We currently support two vocoders, Griffin-Lim algorithm and WaveFlow. You can set --vocoder to use one of them. If you want to use WaveFlow as your vocoder, you need to set --config_vocoder and --checkpoint_vocoder which are the path of the config and checkpoint of vocoder. You can download the pre-trained model of WaveFlow from here.
Or you can run the script file directly.
sh synthesis.sh
For more help on arguments
python synthesis.py --help.
Then you can find the synthesized audio files in ${OUTPUTPATH}/samples.