2.5 KiB
Fastspeech
Paddle fluid implementation of Fastspeech, a feed-forward network based on Transformer. The implementation is based on FastSpeech: Fast, Robust and Controllable Text to Speech.
Dataset
We experiment with the LJSpeech dataset. Download and unzip LJSpeech.
wget https://data.keithito.com/data/speech/LJSpeech-1.1.tar.bz2
tar xjvf LJSpeech-1.1.tar.bz2
Model Architecture
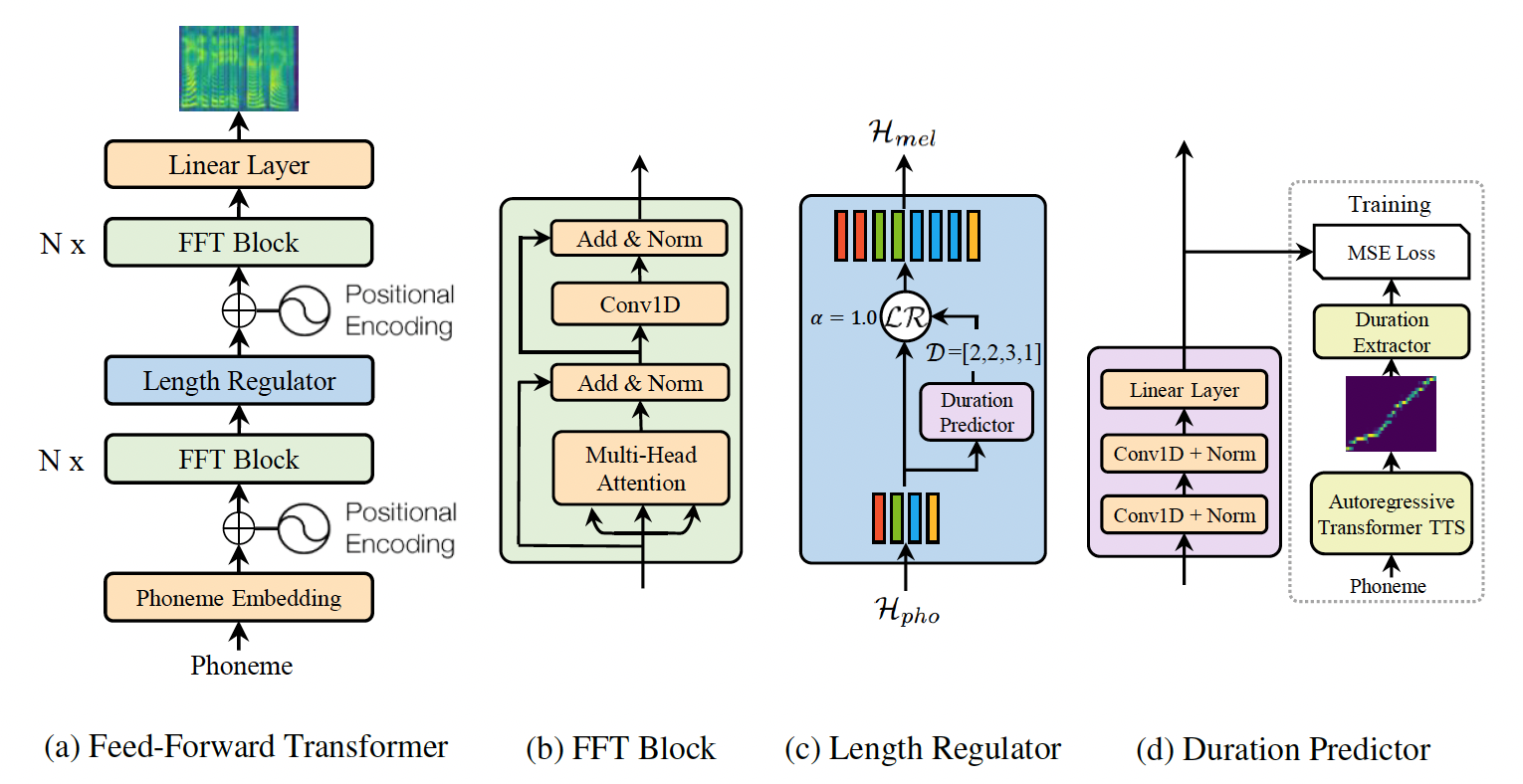
FastSpeech is a feed-forward structure based on Transformer, instead of using the encoder-attention-decoder based architecture. This model extract attention alignments from an encoder-decoder based teacher model for phoneme duration prediction, which is used by a length regulator to expand the source phoneme sequence to match the length of the target mel-spectrogram sequence for parallel mel-spectrogram generation. We use the TransformerTTS as teacher model. The model consists of encoder, decoder and length regulator three parts.
Project Structure
├── config # yaml configuration files
├── synthesis.py # script to synthesize waveform from text
├── train.py # script for model training
Train Transformer
FastSpeech model can train with train.py.
python train.py \
--use_gpu=1 \
--use_data_parallel=0 \
--data_path=${DATAPATH} \
--transtts_path='../transformer_tts/checkpoint' \
--transformer_step=160000 \
--config_path='config/fastspeech.yaml' \
or you can run the script file directly.
sh train.sh
If you want to train on multiple GPUs, you must set --use_data_parallel=1, and then start training as follow:
CUDA_VISIBLE_DEVICES=0,1,2,3
python -m paddle.distributed.launch --selected_gpus=0,1,2,3 --log_dir ./mylog train.py \
--use_gpu=1 \
--use_data_parallel=1 \
--data_path=${DATAPATH} \
--transtts_path='../transformer_tts/checkpoint' \
--transformer_step=160000 \
--config_path='config/fastspeech.yaml' \
if you wish to resume from an exists model, please set --checkpoint_path and --fastspeech_step
For more help on arguments:
python train.py --help.
Synthesis
After training the FastSpeech, audio can be synthesized with synthesis.py.
python synthesis.py \
--use_gpu=1 \
--alpha=1.0 \
--checkpoint_path='checkpoint/' \
--fastspeech_step=112000 \
or you can run the script file directly.
sh synthesis.sh
For more help on arguments:
python synthesis.py --help.