3.4 KiB
TransformerTTS
Paddle fluid implementation of TransformerTTS, a neural TTS with Transformer. The implementation is based on Neural Speech Synthesis with Transformer Network.
Dataset
We experiment with the LJSpeech dataset. Download and unzip LJSpeech.
wget https://data.keithito.com/data/speech/LJSpeech-1.1.tar.bz2
tar xjvf LJSpeech-1.1.tar.bz2
Model Architecture
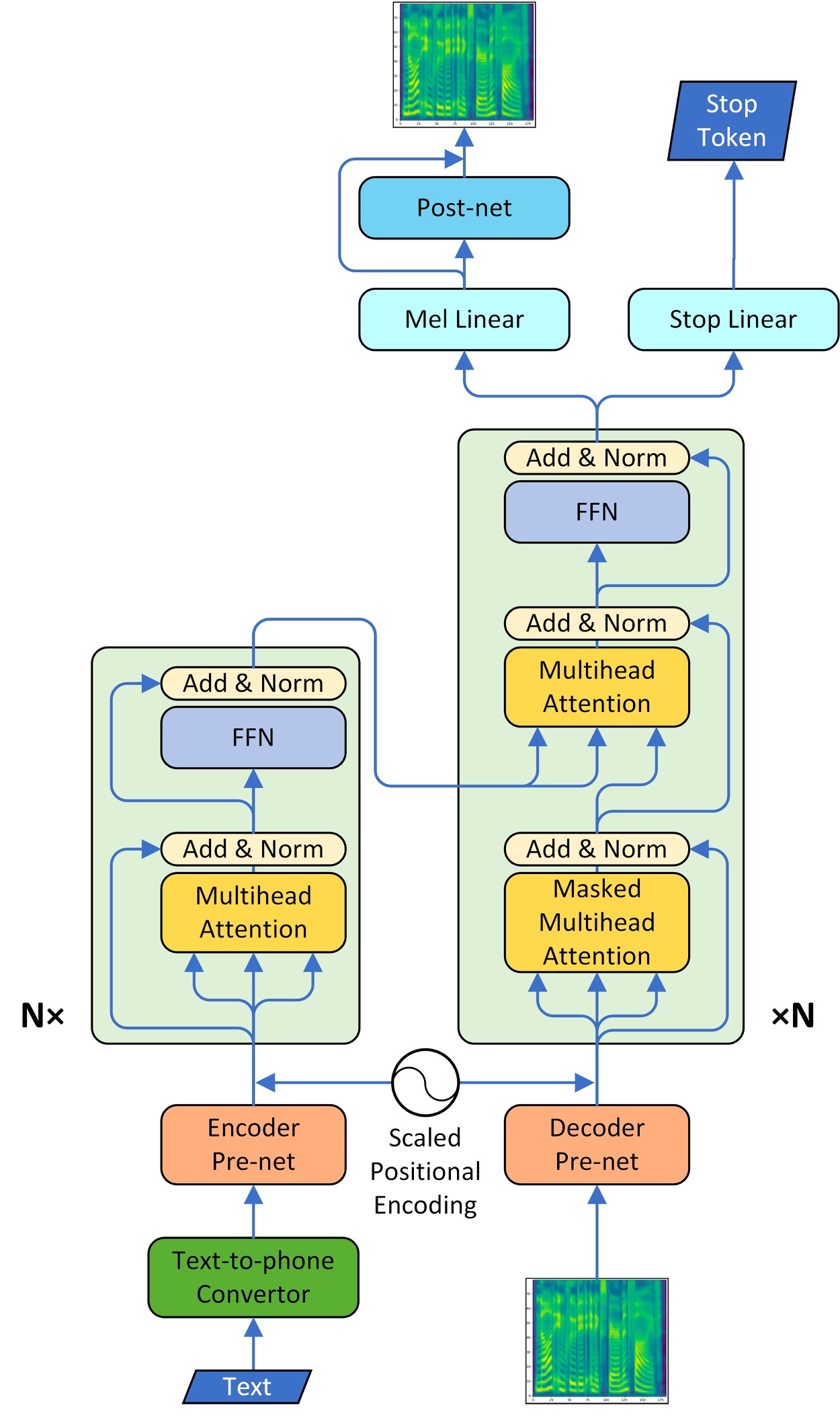 The model adapt the multi-head attention mechanism to replace the RNN structures and also the original attention mechanism in Tacotron2. The model consists of two main parts, encoder and decoder. We also implemented CBHG model of tacotron as a vocoder part and converted the spectrogram into raw wave using griffin-lim algorithm.
The model adapt the multi-head attention mechanism to replace the RNN structures and also the original attention mechanism in Tacotron2. The model consists of two main parts, encoder and decoder. We also implemented CBHG model of tacotron as a vocoder part and converted the spectrogram into raw wave using griffin-lim algorithm.
Project Structure
├── config # yaml configuration files
├── data.py # dataset and dataloader settings for LJSpeech
├── synthesis.py # script to synthesize waveform from text
├── train_transformer.py # script for transformer model training
├── train_vocoder.py # script for vocoder model training
Train Transformer
TransformerTTS model can train with train_transformer.py.
python train_trasformer.py \
--use_gpu=1 \
--use_data_parallel=0 \
--data_path=${DATAPATH} \
--config_path='config/train_transformer.yaml' \
or you can run the script file directly.
sh train_transformer.sh
If you want to train on multiple GPUs, you must set --use_data_parallel=1, and then start training as follow:
CUDA_VISIBLE_DEVICES=0,1,2,3
python -m paddle.distributed.launch --selected_gpus=0,1,2,3 --log_dir ./mylog train_transformer.py \
--use_gpu=1 \
--use_data_parallel=1 \
--data_path=${DATAPATH} \
--config_path='config/train_transformer.yaml' \
if you wish to resume from an exists model, please set --checkpoint_path and --transformer_step
For more help on arguments:
python train_transformer.py --help.
Train Vocoder
Vocoder model can train with train_vocoder.py.
python train_vocoder.py \
--use_gpu=1 \
--use_data_parallel=0 \
--data_path=${DATAPATH} \
--config_path='config/train_vocoder.yaml' \
or you can run the script file directly.
sh train_vocoder.sh
If you want to train on multiple GPUs, you must set --use_data_parallel=1, and then start training as follow:
CUDA_VISIBLE_DEVICES=0,1,2,3
python -m paddle.distributed.launch --selected_gpus=0,1,2,3 --log_dir ./mylog train_vocoder.py \
--use_gpu=1 \
--use_data_parallel=1 \
--data_path=${DATAPATH} \
--config_path='config/train_vocoder.yaml' \
if you wish to resume from an exists model, please set --checkpoint_path and --vocoder_step
For more help on arguments:
python train_vocoder.py --help.
Synthesis
After training the transformerTTS and vocoder model, audio can be synthesized with synthesis.py.
python synthesis.py \
--max_len=50 \
--transformer_step=160000 \
--vocoder_step=70000 \
--use_gpu=1
--checkpoint_path='./checkpoint' \
--sample_path='./sample' \
--config_path='config/synthesis.yaml' \
or you can run the script file directly.
sh synthesis.sh
And the audio file will be saved in --sample_path.
For more help on arguments:
python synthesis.py --help.