|
|
||
|---|---|---|
| .. | ||
| configs | ||
| images | ||
| README.md | ||
| data.py | ||
| model.py | ||
| sentences.txt | ||
| synthesis.py | ||
| train.py | ||
| utils.py | ||
README.md
Deep Voice 3
PaddlePaddle dynamic graph implementation of Deep Voice 3, a convolutional network based text-to-speech generative model. The implementation is based on Deep Voice 3: Scaling Text-to-Speech with Convolutional Sequence Learning.
We implement Deep Voice 3 using Paddle Fluid with dynamic graph, which is convenient for building flexible network architectures.
Dataset
We experiment with the LJSpeech dataset. Download and unzip LJSpeech.
wget https://data.keithito.com/data/speech/LJSpeech-1.1.tar.bz2
tar xjvf LJSpeech-1.1.tar.bz2
Model Architecture
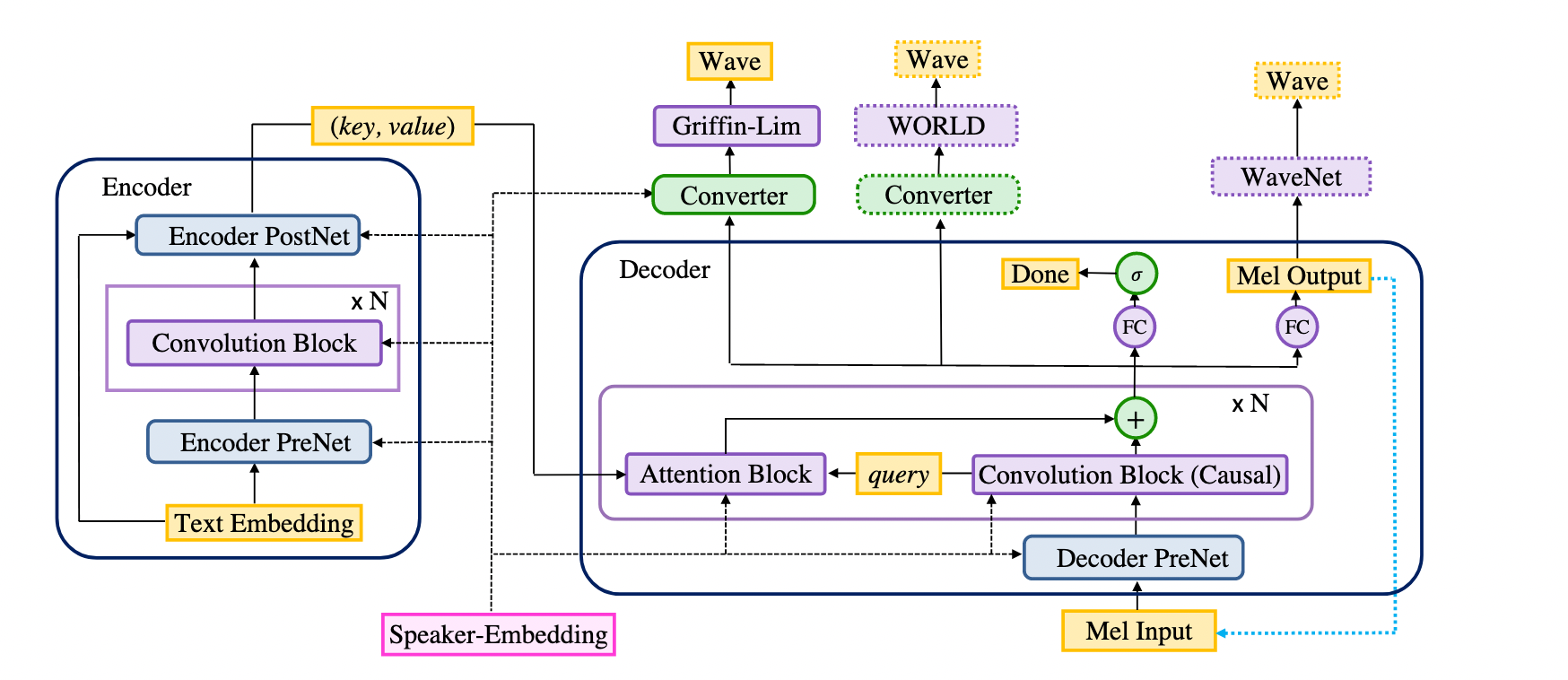
The model consists of an encoder, a decoder and a converter (and a speaker embedding for multispeaker models). The encoder and the decoder together form the seq2seq part of the model, and the converter forms the postnet part.
Project Structure
├── data.py data_processing
├── model.py function to create model, criterion and optimizer
├── configs/ (example) configuration files
├── sentences.txt sample sentences
├── synthesis.py script to synthesize waveform from text
├── train.py script to train a model
└── utils.py utility functions
Saving & Loading
train.py and synthesis.py have 3 arguments in common, --checkpooint, iteration and output.
outputis the directory for saving results. During training, checkpoints are saved incheckpoints/inoutputand tensorboard log is save inlog/inoutput. States for training including alignment plots, spectrogram plots and generated audio files are saved instates/inoutuput. In addition, we periodically evaluate the model with several given sentences, the alignment plots and generated audio files are save ineval/inoutput. During synthesizing, audio files and the alignment plots are save insynthesis/inoutput. So after training and synthesizing with the same output directory, the file structure of the output directory looks like this.
├── checkpoints/ # checkpoint directory (including *.pdparams, *.pdopt and a text file `checkpoint` that records the latest checkpoint)
├── states/ # alignment plots, spectrogram plots and generated wavs at training
├── log/ # tensorboard log
├── eval/ # audio files an alignment plots generated at evaluation during training
└── synthesis/ # synthesized audio files and alignment plots
--checkpointand--iterationfor loading from existing checkpoint. Loading existing checkpoiont follows the following rule: If--checkpointis provided, the path of the checkpoint specified by--checkpointis loaded. If--checkpointis not provided, we try to load the model specified by--iterationfrom the checkpoint directory. If--iterationis not provided, we try to load the latested checkpoint from checkpoint directory.
Train
Train the model using train.py, follow the usage displayed by python train.py --help.
usage: train.py [-h] [--config CONFIG] [--data DATA] [--device DEVICE]
[--checkpoint CHECKPOINT | --iteration ITERATION]
output
Train a Deep Voice 3 model with LJSpeech dataset.
positional arguments:
output path to save results
optional arguments:
-h, --help show this help message and exit
--config CONFIG experimrnt config
--data DATA The path of the LJSpeech dataset.
--device DEVICE device to use
--checkpoint CHECKPOINT checkpoint to resume from.
--iteration ITERATION the iteration of the checkpoint to load from output directory
--configis the configuration file to use. The providedljspeech.yamlcan be used directly. And you can change some values in the configuration file and train the model with a different config.--datais the path of the LJSpeech dataset, the extracted folder from the downloaded archive (the folder which contains metadata.txt).--deviceis the device (gpu id) to use for training.-1means CPU.--checkpointis the path of the checkpoint.--iterationis the iteration of the checkpoint to load from output directory. See Saving-&-Loading for details of checkpoint loading.outputis the directory to save results, all results are saved in this directory. The structure of the output directory is shown below.
├── checkpoints # checkpoint
├── log # tensorboard log
└── states # train and evaluation results
├── alignments # attention
├── lin_spec # linear spectrogram
├── mel_spec # mel spectrogram
└── waveform # waveform (.wav files)
Example script:
python train.py \
--config=configs/ljspeech.yaml \
--data=./LJSpeech-1.1/ \
--device=0 \
experiment
To train the model in a paralle in multiple gpus, you can launch the training script with paddle.distributed.launch. For example, to train with gpu 0,1,2,3, you can use the example script below. Note that for parallel training, devices are specified with --selected_gpus passed to paddle.distributed.launch. In this case, --device passed to train.py, if specified, is ignored.
Example script:
python -m paddle.distributed.launch --selected_gpus=0,1,2,3 \
train.py \
--config=configs/ljspeech.yaml \
--data=./LJSpeech-1.1/ \
experiment
You can monitor training log via tensorboard, using the script below.
cd experiment/log
tensorboard --logdir=.
Synthesis
usage: synthesis.py [-h] [--config CONFIG] [--device DEVICE]
[--checkpoint CHECKPOINT | --iteration ITERATION]
text output
Synthsize waveform with a checkpoint.
positional arguments:
text text file to synthesize
output path to save synthesized audio
optional arguments:
-h, --help show this help message and exit
--config CONFIG experiment config
--device DEVICE device to use
--checkpoint CHECKPOINT checkpoint to resume from
--iteration ITERATION the iteration of the checkpoint to load from output directory
-
--configis the configuration file to use. You should use the same configuration with which you train you model. -
--deviceis the device (gpu id) to use for training.-1means CPU. -
--checkpointis the path of the checkpoint. -
--iterationis the iteration of the checkpoint to load from output directory. See Saving-&-Loading for details of checkpoint loading. -
textis the text file to synthesize. -
outputis the directory to save results. The generated audio files (*.wav) and attention plots (*.png) for are save insynthesis/in ouput directory.
Example script:
python synthesis.py \
--config=configs/ljspeech.yaml \
--device=0 \
--checkpoint="experiment/checkpoints/model_step_005000000" \
sentences.txt experiment
or
python synthesis.py \
--config=configs/ljspeech.yaml \
--device=0 \
--iteration=005000000 \
sentences.txt experiment