|
|
||
|---|---|---|
| .. | ||
| _images | ||
| hparam_tf | ||
| presets | ||
| README.md | ||
| README_cn.md | ||
| __init__.py | ||
| _ce.py | ||
| audio.py | ||
| builder.py | ||
| compute_timestamp_ratio.py | ||
| data.py | ||
| deepvoice3.py | ||
| dry_run.py | ||
| eval_model.py | ||
| hparams.py | ||
| ljspeech.py | ||
| preprocess.py | ||
| synthesis.py | ||
| train.py | ||
| train.sh | ||
| train_model.py | ||
README.md
Deep Voice 3 with Paddle Fluid
Paddle fluid implementation of DeepVoice 3, a convolutional network based text-to-speech synthesis model. The implementation is based on Deep Voice 3: Scaling Text-to-Speech with Convolutional Sequence Learning.
We implement Deepvoice3 model in paddle fluid with dynamic graph, which is convenient for flexible network architectures.
Installation
You additionally need to download punkt and cmudict for nltk, because we tokenize text with punkt and convert text into phonemes with cmudict.
import nltk
nltk.download("punkt")
nltk.download("cmudict")
Model Architecture
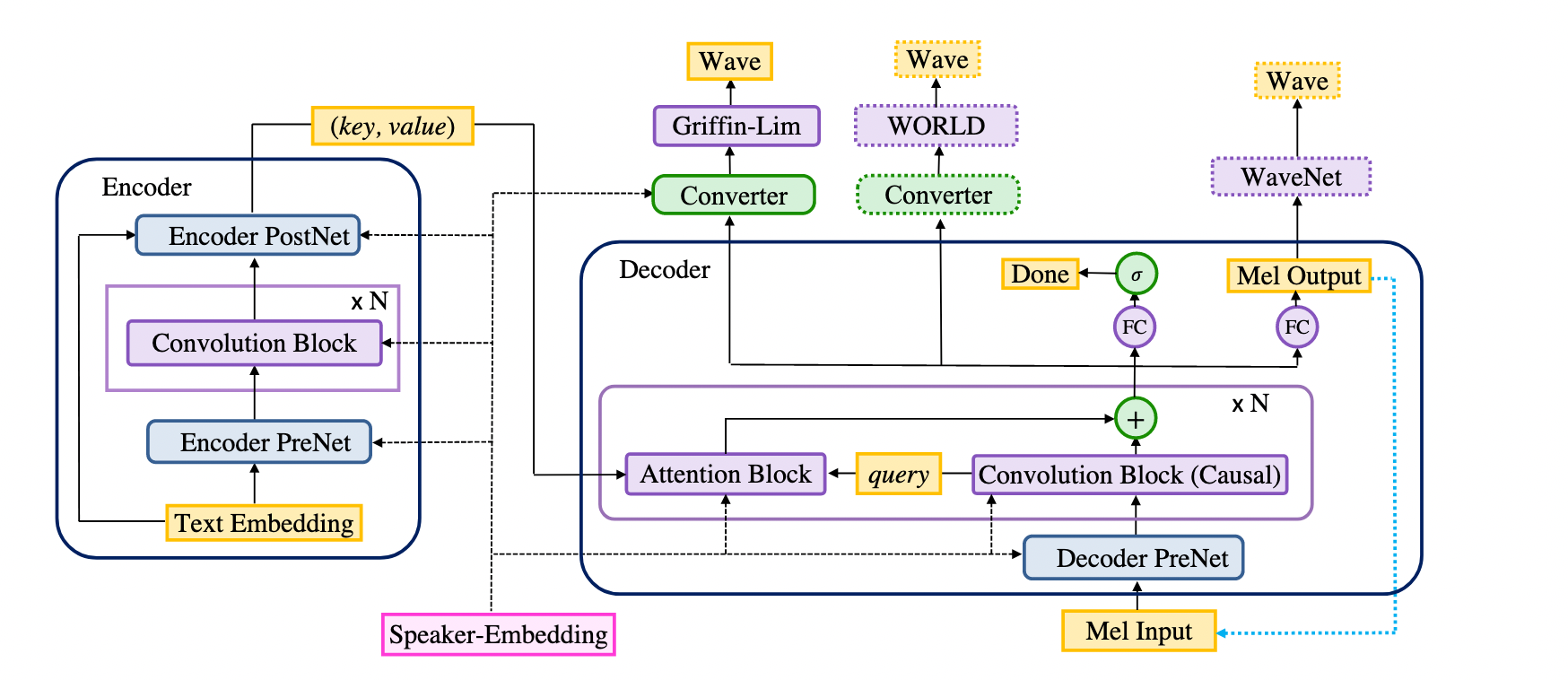
The model consists of an encoder, a decoder and a converter (and a speaker embedding for multispeaker models). The encoder, together with the decoder forms the seq2seq part of the model, and the converter forms the postnet part.
Project Structure
├── audio.py # audio processing
├── compute_timestamp_ratio.py # script to compute position rate
├── conversion # parameter conversion from pytorch model
├── requirements.txt # requirements
├── hparams.py # HParam class for deepvoice3
├── hparam_tf # hyper parameter related stuffs
├── ljspeech.py # functions for ljspeech preprocessing
├── preprocess.py # preprocrssing script
├── presets # preset hyperparameters
├── deepvoice3_paddle # DeepVoice3 model implementation
├── eval_model.py # functions for model evaluation
├── synthesis.py # script for speech synthesis
├── train_model.py # functions for model training
└── train.py # script for model training
Usage
There are many hyperparameters to be tuned depending on the specification of model and dataset you are working on. Hyperparameters that are known to work good are provided in the repository. See presets directory for details. Now we only provide preset with LJSpeech dataset (deepvoice3_ljspeech.json). Support for more models and datasets is pending.
Note that preprocess.py, train.py and synthesis.py all accept a --preset parameter. To ensure consistency, you should use the same preset for preprocessing, training and synthesizing.
Note that you can overwrite preset hyperparameters with command line argument --hparams, just pass several key-value pair in ${key}=${value} format seperated by comma (,). For example --hparams="batch_size=8, nepochs=500" can overwrite default values in the preset json file.
Some hyperparameters are only related to training, like batch_size, checkpoint_interval and you can use different values for preprocessing and training. But hyperparameters related to data preprocessing, like num_mels and ref_level_db, should be kept the same for preprocessing and training.
For more details about hyperparameters, see hparams.py, which contains the definition of hparams. Priority order of hyperparameters is command line option --hparams > --preset json configuration file > definition of hparams in hparams.py.
Dataset
Download and unzip LJSpeech.
wget https://data.keithito.com/data/speech/LJSpeech-1.1.tar.bz2
tar xjvf LJSpeech-1.1.tar.bz2
Preprocessing with preprocess.py.
python preprocess.py \
--preset=${preset_json_path} \
--hparams="hyper parameters you want to overwrite" \
${name} ${in_dir} ${out_dir}
Now ${name}$ only supports ljspeech. Support for other datasets is pending.
Assuming that you use presers/deepvoice3_ljspeech.json for LJSpeech and the path of the unziped dataset is ./data/LJSpeech-1.1, then you can preprocess data with the following command.
python preprocess.py \
--preset=presets/deepvoice3_ljspeech.json \
ljspeech ./data/LJSpeech-1.1/ ./data/ljspeech
When this is done, you will see extracted features in ./data/ljspeech including:
- text and corresponding file names for the extracted features in
train.txt. - mel-spectrogram in
ljspeech-mel-*.npy. - linear-spectrogram in
ljspeech-spec-*.npy.
Train on single GPU
Training the whole model on one single GPU:
export CUDA_VISIBLE_DEVICES=0
python train.py --data-root=${data-root} --use-gpu \
--preset=${preset_json_path} \
--hparams="parameters you may want to override"
For more details about train.py, see python train.py --help.
load checkpoints
We provide a trained model (dv3.single_frame) for downloading, which is trained with the default preset. Unzip the downloaded file with tar xzvf dv3.single_frame.tar.gz, you will get config.json, model.pdparams and README.md. config.json is the preset json with which the model is trained, model.pdparams is the parameter file, and README.md is a brief introduction of the model.
You can load saved checkpoint and resume training with --checkpoint (You only need to provide the base name of the parameter file, eg. if you want to load model.pdparams, just use --checkpoint=model). If there is also a file with the same basename and extension name .pdopt in the same folder with the model file (i.e. model.pdopt, which is the optimizer file), it is also loaded automatically. If you wan to reset optimizer states, pass --reset-optimizer in addition.
train a part of the model
You can also train parts of the model while freezing other parts, by passing --train-seq2seq-only or --train-postnet-only. When training only parts of the model, other parts should be loaded from saved checkpoint.
To train only the seq2seq or postnet, you should load from a whole model with --checkpoint and keep the same configurations with which the checkpoint is trained. Note that when training only the postnet, you should set use_decoder_state_for_postnet_input=false, because when train only the postnet, the postnet takes the ground truth mel-spectrogram as input. Note that the default value for use_decoder_state_for_postnet_input is True.
example:
export CUDA_VISIBLE_DEVICES=0
python train.py --data-root=${data-root} --use-gpu \
--preset=${preset_json_path} \
--hparams="parameters you may want to override" \
--train-seq2seq-only \
--output=${directory_to_save_results}
Training on multiple GPUs
Training on multiple GPUs with data parallel is enabled. You can run train.py with paddle.distributed.launch module. Here is the command line usage.
python -m paddle.distributed.launch \
--started_port ${port_of_the_first_worker} \
--selected_gpus ${logical_gpu_ids_to_choose} \
--log_dir ${path_of_write_log} \
training_script ...
paddle.distributed.launch parallelizes training in multiprocessing mode.--selected_gpus means the logical ids of the selected GPUs, and started_port means the port used by the first worker. Outputs of each process are saved in --log_dir. Then follows the command for training on a single GPU, except that you should pass --use-data-paralle in addition.
export CUDA_VISIBLE_DEVICES=2,3,4,5 # The IDs of visible physical devices
python -m paddle.distributed.launch \
--selected_gpus=0,1,2,3 --log_dir ${multi_gpu_log_dir} \
train.py --data-root=${data-root} \
--use-gpu --use-data-parallel \
--preset=${preset_json_path} \
--hparams="parameters you may want to override"
In the example above, we set only GPU 2, 3, 4, 5 to be visible. Then --selected_gpus="0, 1, 2, 3" means the logical ids of the selected gpus, which correponds to GPU 2, 3, 4, 5.
Model checkpoints (*.pdparams for the model and *.pdopt for the optimizer) are saved in ${directory_to_save_results}/checkpoints per 10000 steps by default. Layer-wise averaged attention alignments (.png) are saved in ${directory_to_save_results}/checkpoints/alignment_ave. And alignments for each attention layer are saved in ${directory_to_save_results}/checkpoints/alignment_layer{attention_layer_num} per 10000 steps for inspection.
Synthesis results of 6 sentences (hardcoded in eval_model.py) are saved in ${directory_to_save_results}/checkpoints/eval, including step{step_num}_text{text_id}_single_alignment.png for averaged alignments and step{step_num}_text{text_id}_single_predicted.wav for the predicted waveforms.
Monitor with Tensorboard
Logs with tensorboard are saved in ${directory_to_save_results}/log/ directory by default. You can monitor logs by tensorboard.
tensorboard --logdir=${log_dir} --host=$HOSTNAME --port=8888
Synthesize from a checkpoint
Given a list of text, synthesis.py synthesize audio signals from a trained model.
python synthesis.py --use-gpu --preset=${preset_json_path} \
--hparams="parameters you may want to override" \
${checkpoint} ${text_list_file} ${dst_dir}
Example test_list.txt:
Generative adversarial network or variational auto-encoder.
Once upon a time there was a dear little girl who was loved by every one who looked at her, but most of all by her grandmother, and there was nothing that she would not have given to the child.
A text-to-speech synthesis system typically consists of multiple stages, such as a text analysis frontend, an acoustic model and an audio synthesis module.
generated waveform files and alignment files are saved in ${dst_dir}.
Compute position ratio
According to Deep Voice 3: Scaling Text-to-Speech with Convolutional Sequence Learning, the position rate is different for different datasets. There are 2 position rates, one for the query and the other for the key, which are referred to as \omega_1 and \omega_2 in th paper, and the corresponding names in preset json are query_position_rate and key_position_rate.
For example, the query_position_rate and key_position_rate for LJSpeech are 1.0 and 1.385, respectively. Fix the query_position_rate as 1.0, the key_position_rate is computed with compute_timestamp_ratio.py. Run the command below, where ${data_root} means the path of the preprocessed dataset.
python compute_timestamp_ratio.py --preset=${preset_json_path} \
--hparams="parameters you may want to override" ${data_root}
You will get outputs like this.
100%|██████████████████████████████████████████████████████████| 13047/13047 [00:12<00:00, 1058.19it/s]
1345587 1863884.0 1.3851828235558161
Then set the key_position_rate=1.385 and query_position_rate=1.0 in the preset.
Acknowledgement
We thankfully included and adapted some files from r9y9's deepvoice3_pytorch.